














Article
Data Mesh in practice: Getting off to the right start (Part I)

This is the third article in a series exploring the key practices and principles of successful Data mesh implementations. You can read part one and two here. The practical learnings explored herein have all come from our recent Data mesh implementation engagement with Roche. However, the use cases and models shared have been simplified for the purposes of this article, and do not reflect the final artifacts delivered as part of that engagement.
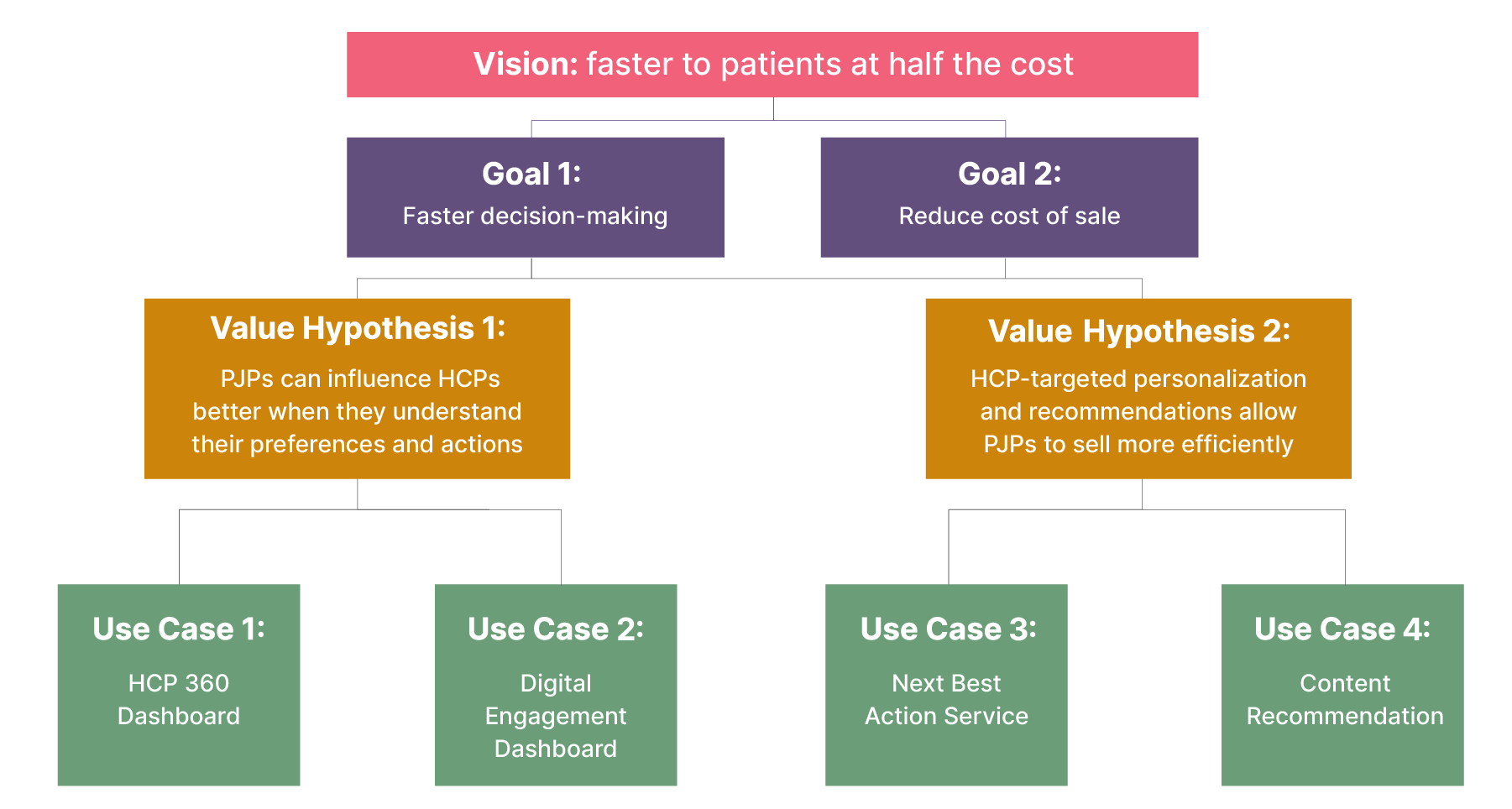
In our previous article, we looked at the operating model changes required to support Data Mesh, and the discovery process we go through to define them using EDGE’s Lean Value Tree (LVT) — ultimately leading to the creation of high value customer outcomes.


The principles of the LVT shape how we approach and think about data products and their creation. This serves as the starting point for the Product stream of the Data mesh Discovery process.


When teams want to start treating data as a product, we recommend working backwards from organizational goals to identifying high-value analytical use cases, and ultimately, which data products are needed to bring the use cases to life.
Throughout the process, relevant stakeholders prioritize their goals and hypothesized use cases, ultimately helping us make informed and value-oriented decisions about which Data Products should be built.
This approach ensures that domain teams and their organizations make intentional, considered choices about the data products they add to the mesh — guaranteeing that teams don’t end up accidentally creating something similar to a data lake monster.
For each identified use case, we take a structured approach to ensure that it can easily be mapped back to the LVT and what we ultimately want to achieve. To help us do this, we use a hypothesis use case template:


It’s a simple framework, but it helps ensure that every hypothesized use case for data products begins with a clear view of its intended value, and a clear definition of how that value will be measured and realized, as seen in the two examples from our work with Roche below:

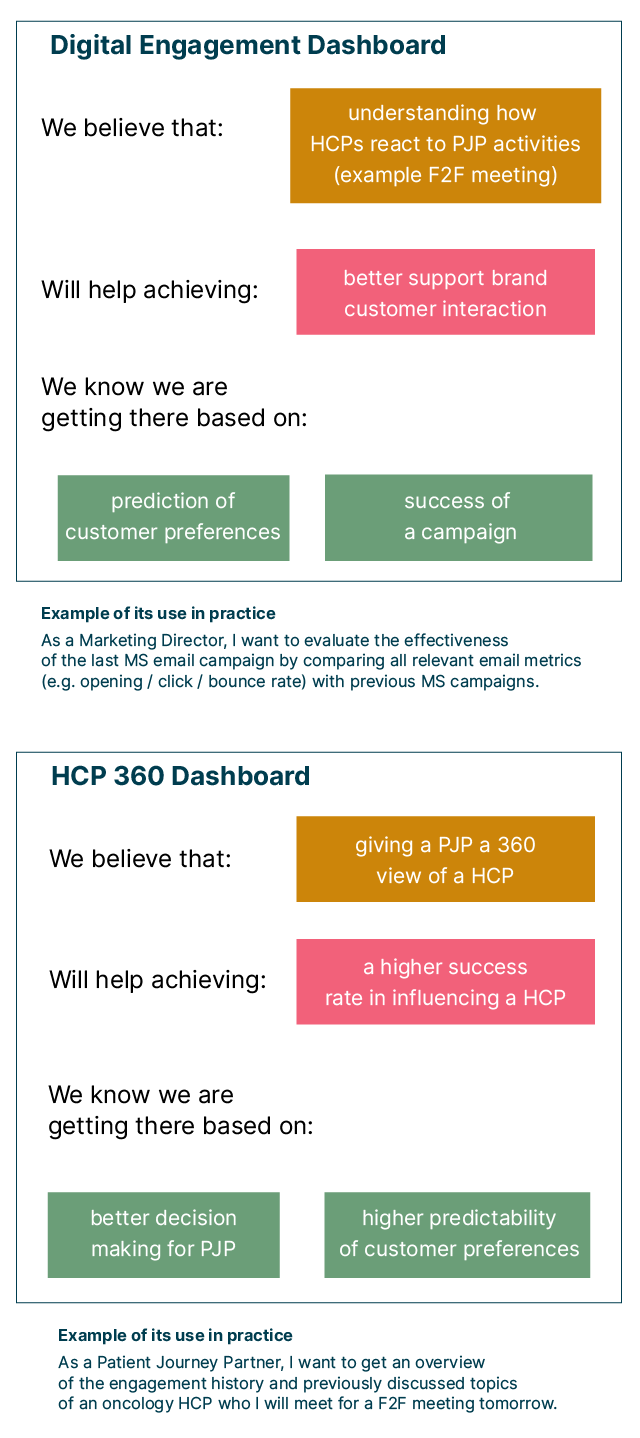
With each use case defined within the template, we can then flow them back into our original Lean Value Tree:

From there, the outlined use cases are prioritized based on what the business wants to achieve and pursue. We use the following data use case prioritization template for this, but any similar prioritization method is equally suited for the task:


Whichever framework you choose to follow, it’s critical that the right IT and business stakeholders are involved at every stage of this prioritization process. You want to begin your journey with a complete view of what’s most important to the domain, and which route is best to get there, so gathering broad input is highly valuable.
At this stage, it’s worth noting the role that product thinking plays in the Data Mesh. Data products are named as such because that’s exactly what they are — they’re products, selected and valued by consumers.
To deliver its potential value, Data Mesh requires the domains building products to understand and apply the principles of product thinking. For some — especially those used to working closely with customers and responding to their needs — that may come naturally. For others, it may require enablement and upskilling.
In line with product thinking best practices, domain decision-makers joining the Data Mesh should understand principles including:
A data asset can be any entity that is composed of data — such as databases or application output files.
Data products however are:
Created to serve a specific user-driven goal as identified in your Lean Value Tree
Subject to clearly defined SLOs
Owned by a single domain or stakeholder and maintained by a single data product team, who are responsible for their upkeep
What makes up a data product


Once you’ve got a clearly prioritized list of use cases, it’s time to start identifying the data products that are best suited to satisfy and enable them.
Here we introduce a simple data product template that helps articulate exactly what a data product needs to do, and how it will do it:


The following six questions have helped guide the product stream of our discovery process, allowing domains to determine exactly which products they need to create, and how those products should come together to deliver maximum value.
Who will use the data product? And which stakeholders does it most directly serve?
If we would expose this data product, would it be valuable for consumers? And are there any other stakeholders or domains that would be interested in this data product?
How will they consume and engage with the data product?
Which tasks or actions will they use the data product to support, and how can we meet their consumption requirements at that point?
How would those consumers access or consume this data product?
Which input data is required for the data product? Or what sources will need to be used to build and maintain the data product?
Together, the answers to those questions enable us to fill out our Data Product template as follows:


In this article, we intentionally choose a 360-degree view data product because we encounter 360-degree data solutions very frequently. In this case, the HCP 360 Data product isn’t just created by pulling together all data that’s relevant to HCPs — every input is carefully considered and intentionally added to best meet the needs of our defined consumers.
For example, the first iteration of the product only included data on how HCPs responded to digital engagements, while the second iteration added vital information about recommendations and next steps. This iterative approach helped us build up a product that was extremely relevant and valuable for consumers, and served them with what they really needed.
Once you’ve identified a collection of data products using the input templates, you can then start to draw out a data product interaction map, as shown below:


The data product interaction map clearly shows how data sources and integration sources feed into both source-oriented and consumer-oriented data products. But the most valuable aspect this map helps teams do is start to identify overlapping areas of data usage between prioritized data products.
Identifying this can help teams adjust the boundaries of their data products and make sure effort isn’t needlessly duplicated, or even devise ways to unite potential data products to serve multiple, closely-linked needs.
Over time, multiple interaction maps, that feed into one another , can be brought together to create a single integrated data product landscape for a domain, as pictured below:


Here the HCP 360 data product is used as an input for the Digital Engagement Data Product. Using the integrated view we identified four data products (in yellow), that serve both use cases and whose boundaries can be logically merged.
The integrated data product interaction map provides us with an overview of all the foundational data products within a given domain. The map will evolve as new use cases are prioritized and onboarded into the Data Mesh, continuously giving teams a clear view of their data product landscape that they can use to make informed decisions about data product development or evolution.
In our experience, one of the most common reasons behind low data reusability is data simply not being available in the format different teams or use cases need. When we treat data as a product, we make conscious decisions based on how the data product will be used for each use case it serves, enabling high interoperability and reusability.
Before going any further, let’s first break down a few key terms:
Service-level objectives (SLOs) are the targeted levels of service, measured by SLIs. They are typically expressed as a percentage over a period of time. Eg. 99% availability over a three-month period
Service-level indicators (SLIs) are the metrics used to measure the level of service provided to end users (e.g., availability, latency, accuracy)
Error budgets are the acceptable levels of unreliability for a service before it falls out of compliance with an SLO
In Data Mesh, we use SLOs to make sure that individual data products work as expected. If outages or disruptions exceed the defined error budgets, that forces the product teams to check the backlog to improve the reliability or stability of the data product.
For example, an SLO of “99.5% of the transactions from previous day shall be processed before 9am every day” has an error budget of “0.5% of transactions missed to be processed per day” and this error budget can for example be set at, “2% of transaction missed per month”. Should the error budget be exceeded or used up, it amounts to a violation of the SLO.
We use a discovery exercise called Product Usage Patterns to collectively brainstorm and understand how stakeholders wish to use a data product, and what their key expectations are for it. This enables us to determine the SLOs that need to be set for individual data products.


As a final step, we mapped Roche’s identified data products to the domain LVT using the following Data Mesh Template:


For Roche, that looked like this:


In terms of change management for Data Mesh, this is our most value creating and critical step. This tangible association of the data to one or more business goals , is what turns data into a data product - justifying its existence and clearly showing how it supports the domain and the wider business. Within this definition, it has measures of success, an owner, and a future roadmap. At this stage everyone is clear about the expected business outcome and their role in achieving it.
Depending on the goals of the domain, business decision makers can make a conscious decision about which goals they want to achieve, thereby helping them prioritize which data products to build.
In addition to their hypothesized value and business purpose, for each data product, we clearly define the following criteria, to help everyone understand their purpose and value:
Minimum requirements for Data Products
Mandatory:
Owner / Steward (first point of contact for the data product, approver of access)
Data Product name (unique to the data domain)
Description of the Data Product
Data sharing agreement (published on a common marketplace catalog (e.g. Collibra))
"Open Access" or "Access Approval Required" (approval granted by DP Owner)
Published Data Access Policy: Define who is/isn't allowed access to the data
Distribution rights: Whether modified (aggregated, filtered, merged) or unmodified data can be distributed to third parties by the consumer
SLO
Port (a delivery mechanism for the Data Product)
Business Domain (Business Function)
Data Privacy, Classification and compliance (*mandatory only for regulated industries such as healthcare, banking etc.)
With the LVT, the Data Product Interaction map and the Data Product checklist all created, domains can move onto the final aspect of our discovery, and start making informed technology and architecture decisions.
In the fourth and final article in this series, we’ll look at those decisions, and walk you through some of the ways Data Mesh has helped organizations build a strong technical and architectural foundation for their Data Mesh operations.

