














Data science and analytics
This is how data governance builds trust

How often have we heard these?
“Data governance is so BORING.”
“Data governance is just there to stop things.”
“All data governance does is write policies.”
“Didn’t buying this tool mean we’re already doing data governance?”
Many business stakeholders see data governance as a chore. But what happens if you don’t do it?
Here are a few — true — cautionary tales:
A sales report being out by “a few billion” takes five months and three teams to track the root cause: having a phone number next to the field where sales amounts were captured, which caused all numbers to be transposed.
A data platform was built, used to forecast likely machine repairs (including parts needed). It also forecast likely profitability of those repairs
The platform produced a Sales report, feeding the CEO the value of sales from repairs. Three years in, someone noticed the report was off a few "billion" dollars, compared to equivalent SAP system report. It had been happening from day one.
Investigation took almost five months;
2 months from the reporting team, concluding it was a transformation team issue.
2 weeks from the transformation team, concluding it was an ingestion team issue.
2 months with the ingestion team concluding there you problems because they had perfect data quality rules.
The product owner then got in touch with the users doing the data entry. They found that the mechanic doing the data entry used a manual form. The form had the customers phone number right above the space for capturing the sales value of the repair. Sometimes they would swap the phone number with sales amount.
The teams had their own slice of silo with no overall governance, and nobody knew the business process of how the numbers were reported together, critical sales numbers on which the CEO ran the business strategy, incorrect for three years.
A major international manufacturing company lacked controls over how ERP systems and their data formats were to be integrated, causing serious issues where no revenue was properly recognized. Amazingly, this led to the company divesting from countries.
A major international manufacturer integrated a number of local ERP systems for managing orders, contracts, financial planning etc. Data was shared via CSV exports from those ERPs. Some systems changed the decimal separator an the importing system did not check the number of columns per row. The columns of order in local currency, invoiced in local currency and number of new orders were next to each other. As a result, in some countries the "cents" part of the local currency got to be the "number of orders".
This only surfaced when operations in said country ceased sales activity (thus no orders, but surely invoiced revenue) happened.
The impact on net working capital was double-digit millions. and based on the correct info they would not have divested in that country.
As you can see, poor data governance can have significant real world implications. So, what can we do to create good data governance practice and prevent these outcomes?
Typically, implementing data governance from a standing start is like the traditional approach to building platforms: layer by layer, one piece on top of another. Whereas, if you believe tool vendors, you could just buy their tools and have data governance. For the avoidance of doubt you won’t have data governance, you’ll have a tool.
Ignoring vendors, and taking the traditional approach means establishing councils, working groups, writing policies and standards, processes and procedures. These then need to be rolled out across the enterprise.
This approach is distant from the problems the enterprise is facing, for example If errors are creeping into order fulfillment, how will a meta-data management policy or buying a data cataloging tool solve them? The short answer is it won’t. What’s more, any business engagement the data team has accrued from identifying the issue to be fixed, will disappear if the issue is not fixed.
Demonstrable, measurable positive outcomes are vital in maintaining engagement.
A traditional approach may get you enterprise governance, eventually, you’re not solving the problems that require data governance. So, how do you solve those problems?
At Thoughtworks, we have a number of sensible defaults that guide our decision making. These provide us with the best approaches in most circumstances. One of these sensible defaults that can improve delivery outcomes is taking a problem domain and delivering solutions a thin slice at a time. We’ve found this is the easiest way to achieve those demonstrable, measurable, positive, outcomes.
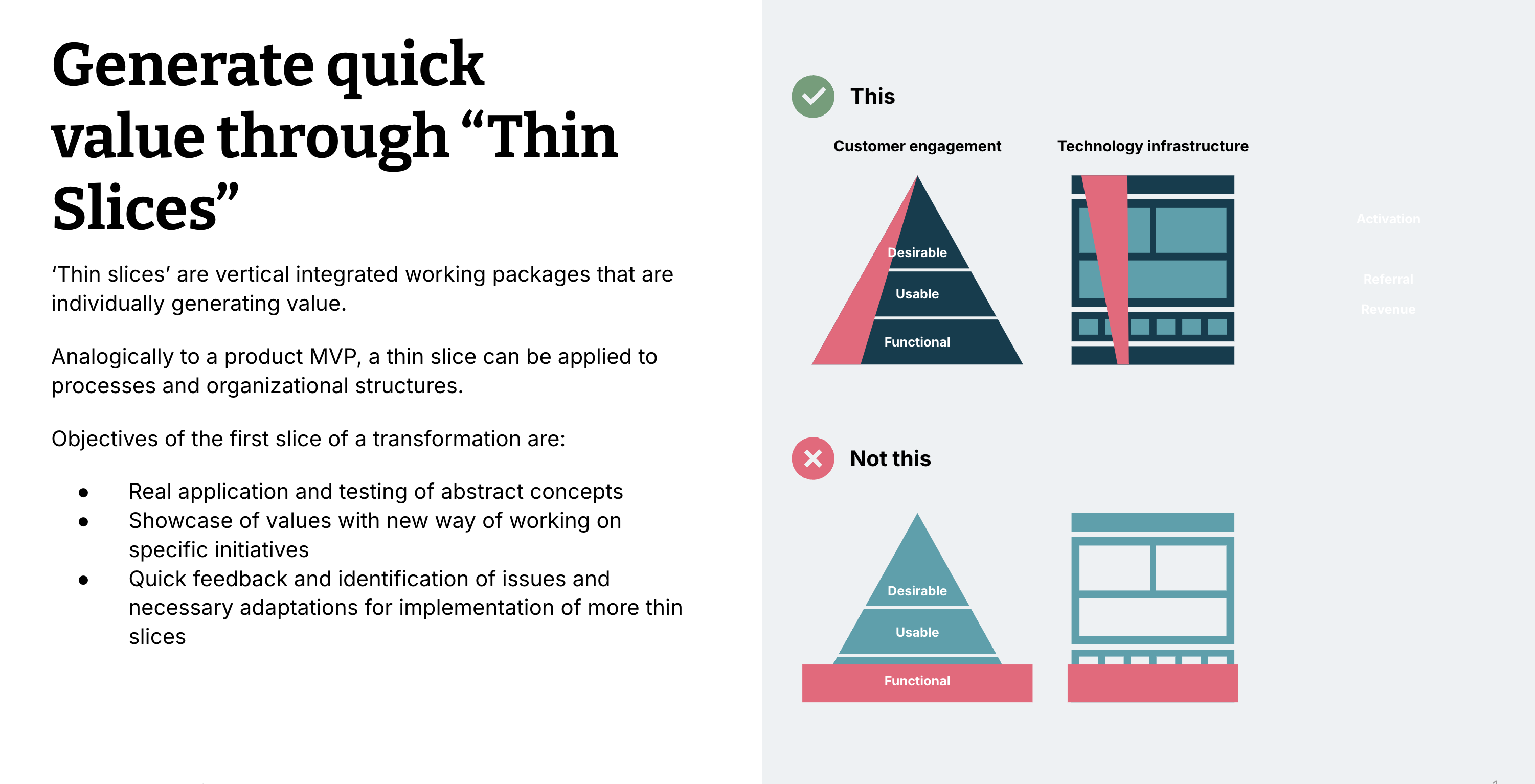
The 'thin slice' is a concept from lean product development whereby a very small, vertically-integrated increment of work is identified. This is used to begin learning from tangible development in practice, while also meeting business needs.
Data governance is core to any successful data transformation, especially a data mesh. Data mesh principles state that data governance needs to be applied and enabled systematically and invisibly within platform capabilities, and observably in each data product as early as possible in their lifecycle (this is what we refer to as “federated computational governance”).
If we’re using a framework, such as DCAM or DAMA’s DMBOK, it should recognise that every enterprise’s problem and opportunity space is unique. We should only use a framework that accelerates identification and resolution of issues and creation of valuable outcomes in a thin slice is vital.
Some frameworks exist to assess, plan the development of a data management capability with the implicit assumption that adopting them holistically is intrinsically valuable and worthwhile to see through. This is not compatible with thin slicing. Other frameworks acknowledge they are a collection of patterns and practices to be applied situationally. This is more compatible with a thin slicing approach and more useful. Thin-slicing recognizes every enterprise’s problem and opportunity space is different from other enterprises. Using (part of) a framework that accelerates identification and resolution of issues and creation of valuable outcomes in a thin slice is vital. Valuable outcomes don’t just include money saved, but include reduced risk, increased customer satisfaction, a reduction of friction either internal or external, reduced time to market and so on. |
The entire process (a full discussion can be found here) of mesh specification, design and implementation is beyond the scope of this post, but we will focus on one part of the process — data domain design.
Identifying data products inside a data mesh is possible only by understanding the business domains and their respective strategic goals. Products can then be aligned accordingly. As part of this process, you will start to identify the thin slices that create the most impact and identify the processes, systems and stakeholders that drive those domains.
The real world value of those thin slices will determine which one you tackle first.
For each slice, and only for the context of that slice, we define what good data governance looks like, such as documenting:
Relevant data models
Accountabilities
Service level objectives and indicators
Quality expectations,
Critical data
Key terms and definitions
Issue identification and resolution processes.
Thin-slicing isn’t about simply applying one aspect of data governance while ignoring all the others. You can’t do thin slicing by, for example, defining a comprehensive data quality framework that applies across the whole enterprise, but ignore standards for privacy or data security. Instead, you need to apply those parts of data governance that are relevant to your specific use case. Thin-slices should quickly lead to a proof of value, not just a proof of concept — that it delivers some sort of impact.
None of this means there’s no central data governance team. While a mesh promotes federated data governance, that’s for BAU; guardrails and consistency cannot be guaranteed at a federated level, of course. That’s why there should be a central team accountable for the success of data governance throughout the enterprise. They will iterate frameworks and policies as more thin slices are implemented. They should also be able to adapt in response to the needs of the use cases driving the thin slices.
For thin slices, the data governance team will be different from the standard conception of a data governance team with its stewards, privacy and analysts. This new style of team would need to be cross functional, consisting not just of the data management expertise but experience designers, change specialists and even technical expertise. They will need to be closely aligned and working across and alongside the teams working to implement those thin slices, doing data product delivery.
Looking at the major international manufacturer in our example and their integration of ERP software, the problem statement suggests that the order process, from capture to fulfillment to invoicing, is the thin slice to address.
Order processes for manufacturing cut across the whole range of data management concerns, from Governance through to quality and master and reference data management. How do we go about establishing data governance and good management of that data in that flow?
For that flow of information we need to understand;
The types in play, e.g. master data, reference data and metadata
What standards or patterns can we apply?
Which stakeholders have accountability for which parts of the flow
What is the critical data at each stage of the flow expectations of quality for it?
How measure quality, publish results and report/resolve issues
How integrated change management and data management are.
And this is the key point, it’s all in service of the one thin slice.
We are not interested in setting up boards, policy frameworks or investing in enterprise tools unnecessarily. We just focussed on applying data governance best practices to the *specific* issues in that flow.
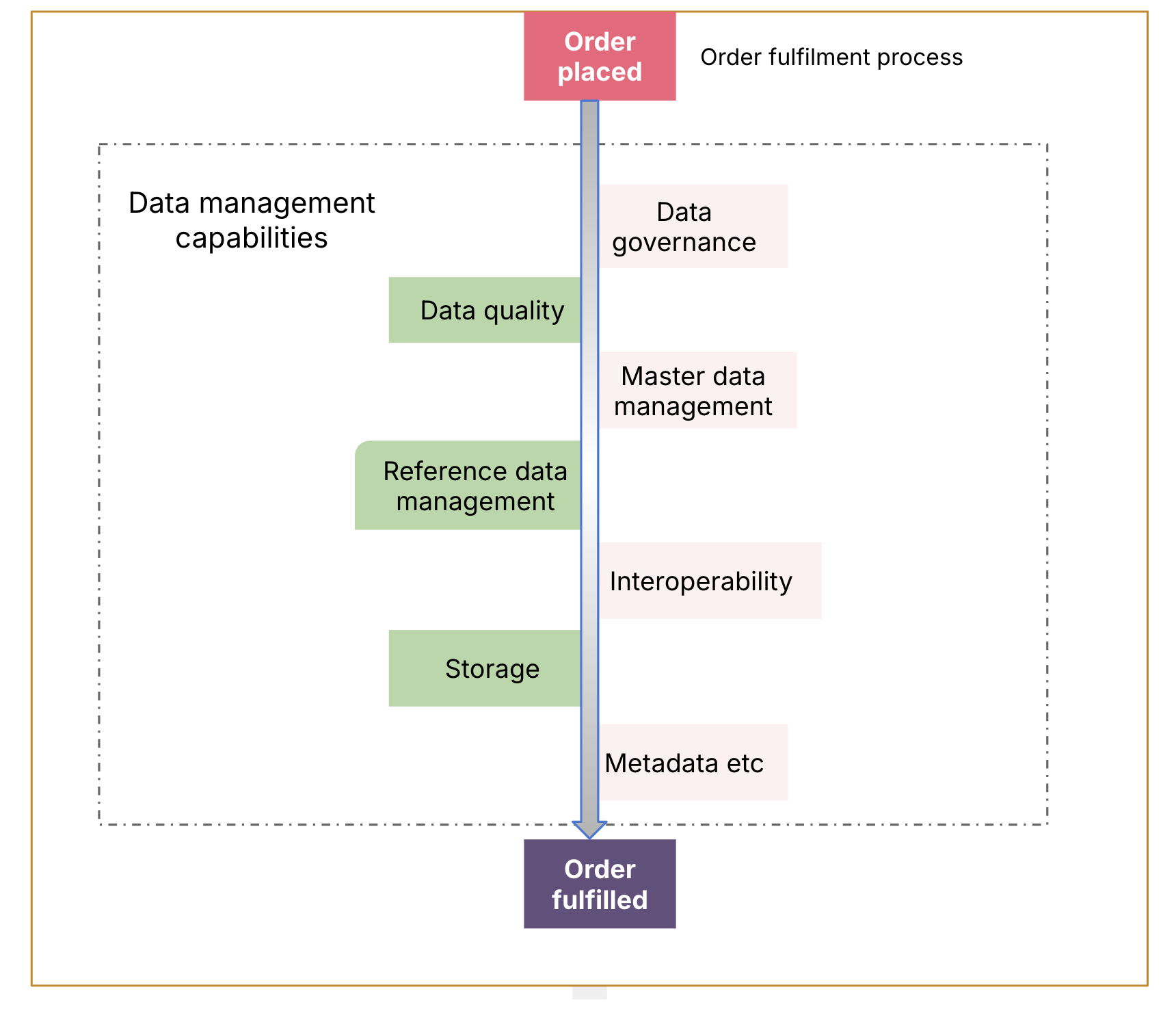
Let’s examine each of these in turn;
For orders the kinds of data we’re thinking about are;
Product and customer master data, including descriptions, allowed quantities, etc.
We have reference data such as addresses and currencies
We have the actual transaction data, i.e. quantities and values and taxes
We have the metadata describing each of the attributes, their definition, their precision (for numbers), allowed values for dates, times etc.
What standards or patterns can we apply? For example;
Is master data managed in one place, centrally, or is it managed in multiple places and synced?
Can we use the ISO 20022 standard to represent addresses?
Why shouldn’t we apply the Dama Dimensions to DQ? Or ISO 4217 for currencies
Which stakeholders have accountability for which parts of the flow?
Whose compensation depends on getting this right?
Who has the wherewithal to approve and mandate change?
What is the critical data at each stage of the flow?
What data is required to complete the stage of the process and needs to be of unimpeachable quality for that purpose?
(if necessary) What data is required for reporting the status of this stage to external stakeholders, like regulators or the market?
What are the expectations of data quality for at least that critical data as each part of the flow
Expressed in terms of completeness, consistency, accuracy, timeliness, uniqueness and validity, what is the expectation of quality for (at least) the critical data in that flow
What is the process for measuring quality, publishing results, with reporting and resolving quality issues, how and when;
Is data profiled for quality assurance?
Are the results of the quality profiling published?
issues are raised and who is responsible for resolving them and reporting progress on resolutions?
How integrated are change and data management, for example are data management best practices integrated in your CI/CD pipelines, such as;
Demonstrating standards compliance? E.g data formats etc.
Demonstrating DQ requirements are being met at design time? E.g. to enforce completeness, validity and consistency checks
Reference and master data being sourced appropriately?
The answers to these questions can be developed into fitness functions, an automated governance technique and applied to data at rest and in motion. Kiran Prakash in his article Governing data products using fitness functions, explains how they can be created.
Overall, the central data team/data governance team will be asking the delivery teams to bake these requirements into their solutions and CI/CD pipelines, one thin slice at a time and they’ll be vital partners in this process.
Thin slices are the gateway to quicker showcase of value in Data Governance, and faster learning cycles to optimize Data Governance methods & practices and most importantly ensuring that Data Governance is an enabler, not a blocker.
It’s not enough that there’s good data governance, but the governance team needs to be seen enabling data governance positively and proactively, aligned with business needs, and at Thoughtworks we believe thin slices are the easiest way to achieve this.
Let us know if you need any help.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

