














AI and ML
Effective machine learning (Part I)

In Part I of our Effective Machine Learning (ML) series, we wrote about the traps that organizations fall into when scaling ML and how critical it is to keep feedback loops short. In this post, we’ll share three principles and related practices that will help teams keep feedback loops short.
It’s common to see teams test the quality of ML models, predictions and software behavior through manual prodding and ad-hoc analysis. While this is needed in early phases of an ML project, it doesn’t scale well and becomes tedious and error-prone very quickly.
As we improve our understanding of a model’s implicit quality measures, they should be made explicit and visible with minimal manual intervention. By doing so, we (a) reduce the non-trivial toil needed to inspect the quality of our models, and (b) ensure that every release candidate is automatically inspected for its quality before it gets into the hands of users. For example:
Instead of manually testing the ML model, automated tests should be part of the model’s continuous integration (CI) pipeline.
Instead of manually debugging and inspecting to understand why a model produced particular predictions, we can automate explainability processes and mechanisms as part of a model’s path to production.
Automation goes a long way to reduce toil and burden. By automating repetitive tasks (e.g., manual testing, model quality checks, software deployments), we can free people for higher-value, problem-solving work.
Here’s a flavor of what an automated path to production could look like. When a code change is committed and pushed, a continuous integration (CI) pipeline automates the following:
Run a series of tests (e.g. unit tests, model training tests, API tests)
Trigger large-scale training
Run model quality tests
Build and publish model
automatically deploy the image to a pre-production environment
Run post-deployment tests
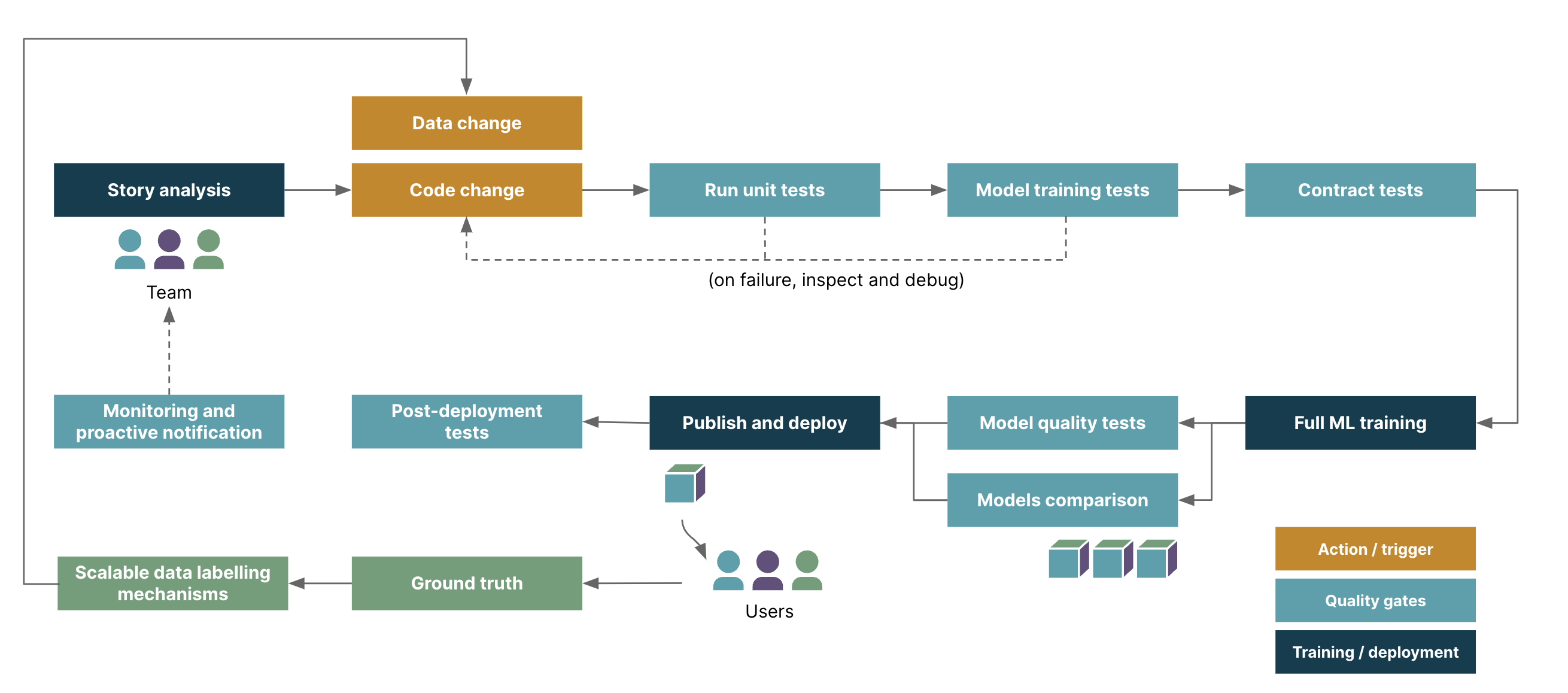
When the entire CI pipeline is green, it means the trained model has passed all the fitness functions we defined, and we can confidently deploy changes to production. This helps us reap the benefits of continuous delivery such as lower-risk releases, lower costs, higher quality and faster time to market.
In the software industry, while we may not lose a finger to malfunctioning equipment, we face other engineering risks, such as deploying a code change that brings down entire systems and costs a company millions of dollars, or deploying biased ML models that could cause harm to others.
We can and must build safety checks (e.g., unit tests, model quality tests, bias tests, etc.) into our path to production and ways of working, to minimize the risk of adverse outcomes. Beyond that, we can also assess, model and mitigate risks of the software we are creating with a special emphasis on the impact of your work on individuals and society.

If you’re interested in how this looks like in your ML journey, please get in touch with us. Stay tuned for the upcoming parts of the Effective ML series:
Part III: Improving flow
Part IV: Taming cognitive load
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

