














在软件开发和架构设计中,反模式(Anti-pattern)[1] 是一种特定的模式,它看似提供了一个有效的解决方案,但却没有考虑到更大的背景或长期后果,因此通常会导致更多的问题和复杂性。反模式可能是由于开发人员在解决特定类型问题时没有足够的知识和经验,或者在错误的上下文中应用了正确的模式而导致的。
DevOps领域是反模式的高发区。开发团队虽然知道最佳实践的好处,却总是由于各种各样的约束而放弃,去选择那些反模式。还有一些情况是,开发团队以为这些反模式就是最佳实践,从而在错误的道路上越走越远。
我们这个系列会着重介绍一些DevOps中常见的误以为是最佳实践的反模式及其带来的危害,希望能为广大开发者避坑。
反模式 - 特性分支
我们要介绍的第一个反模式是特性分支,这无疑是一个充满争议的话题。早在16年,我的同事刘尚奇就写了一篇关于特性分支的《Gitflow有害论》,现在仍然有很高的讨论度[2]。
这是因为特性分支,以及近几年在它基础之上发展起来的AoneFlow等其他分支模型,几乎已经在整个行业成为了“事实标准”。然而它的危害也很大,特性分支分支也好,AoneFlow也罢,都不利于持续集成。
我们先来统一一下语言,看看什么是特性分支,以免在不同的上下文下讨论问题。
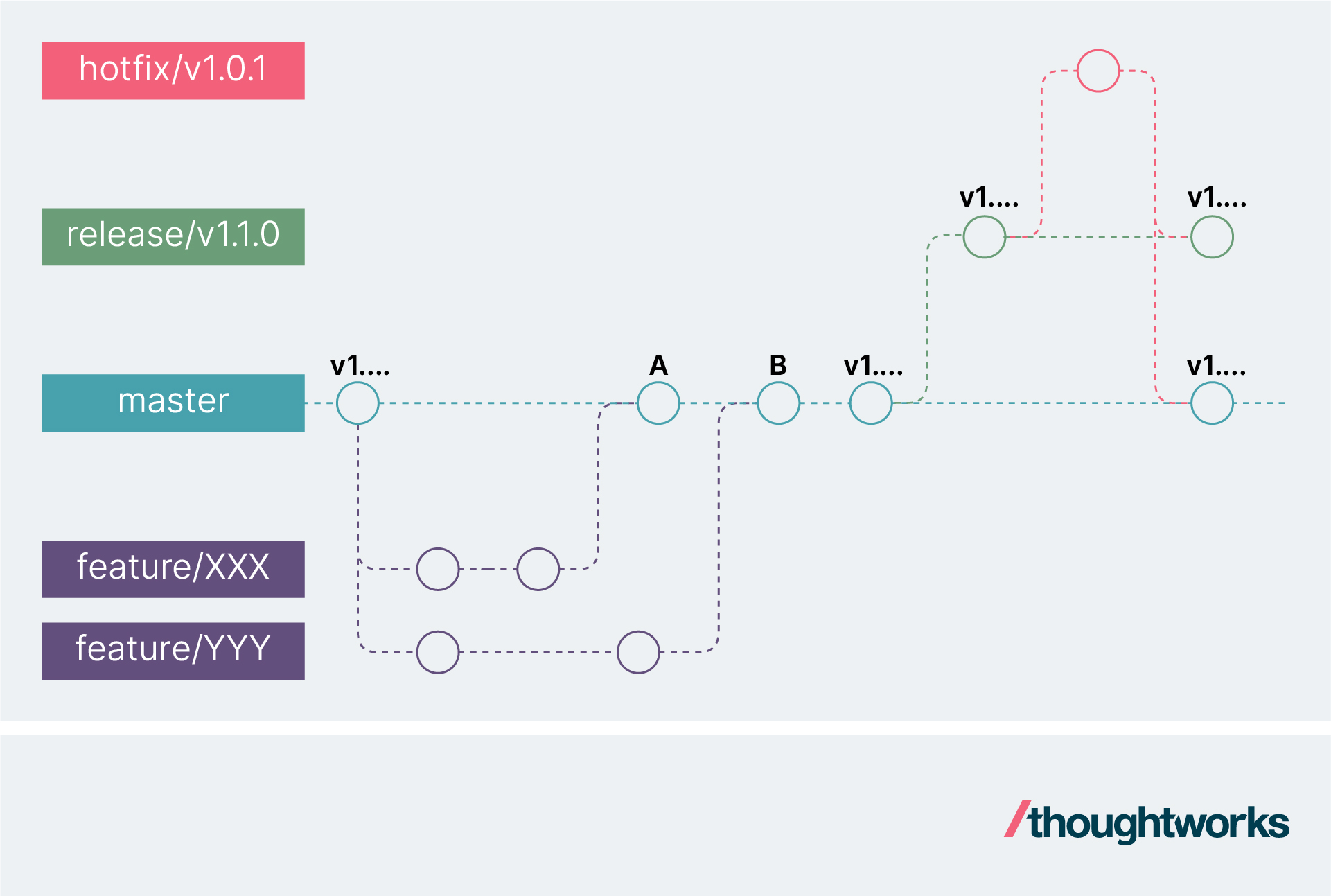
特性分支开发的流程图
上图是一个常见的特性分支开发流程图,其开发过程如下:
不同的特性需求在开发前会拉出各自的特性分支(feature/XXX和feature/YYY)
分别开发完成后会向主干(master/main)合并(合并点A和B) 当前交付的需求都开发完成后,会在主干上拉出发布分支(release/v1.1.0),发布到生产
如果生产环境出现问题,会从发布分支的基础上拉出一个hotfix分支(hotfix/v1.0.1),进行修复
修复完成后合并会发布分支,发布这次修复
同时将该修复合并(通常是cherry-pick)回主干。
你的团队也可能采用了其他特性分支的变种(比如用develop或release作为主干或共享分支等)。只要拉出来的特性分支长时间没有合并回主干,就相当于没有做持续集成,就是一种DevOps反模式。
造成的问题
我们在做持续集成时,最常听到的一句话就是:
越是痛苦的事情,越要频繁做(if it hurts, do it more often)
因为频率可以降低复杂度[3]。分支合并(即代码集成)也是一个非常痛苦的事情,因此要通过频繁合并来降低这个痛苦。一年一度的DORA报告[4]也显示,高绩效团队总是有很高的集成频率。
如果特性很快开发完成并合并到了主干,合并起来就不会太痛苦,这种属于非典型的特性分支,是没有问题的。
但我们看到的往往是长时间不合并到主干的特性分支(即长时间不做集成),这意味着主干上已经有了很多其他人的代码,与当前特性分支的差异会很大,合并冲突的风险和因合并而产生缺陷的风险都很高。这也就是我们常说的合并地狱[5]。
我服务过的客户曾经遇到过一个问题,有一个功能明明在前一天还好好的,突然第二天就不能用了。经过长时间排查才发现,原来是有一个一年前的特性分支终于开发完毕,进行了合并和集成。尽管开发人员在合并前汗流浃背地解决了所有冲突,但仍然在不经意间破坏了其他功能。
有同学可能会问,我的特性分支虽然不合并到主干或公共分支,但会频繁将主干或公共分支合并到本地的特性分支,并在本地运行构建、单测等来确保集成成功,这样是否可以呢?答案也是否定的。因为此时你代码分支的head和其他代码分支的head也是有很大差异的,同样会造成合并地狱。
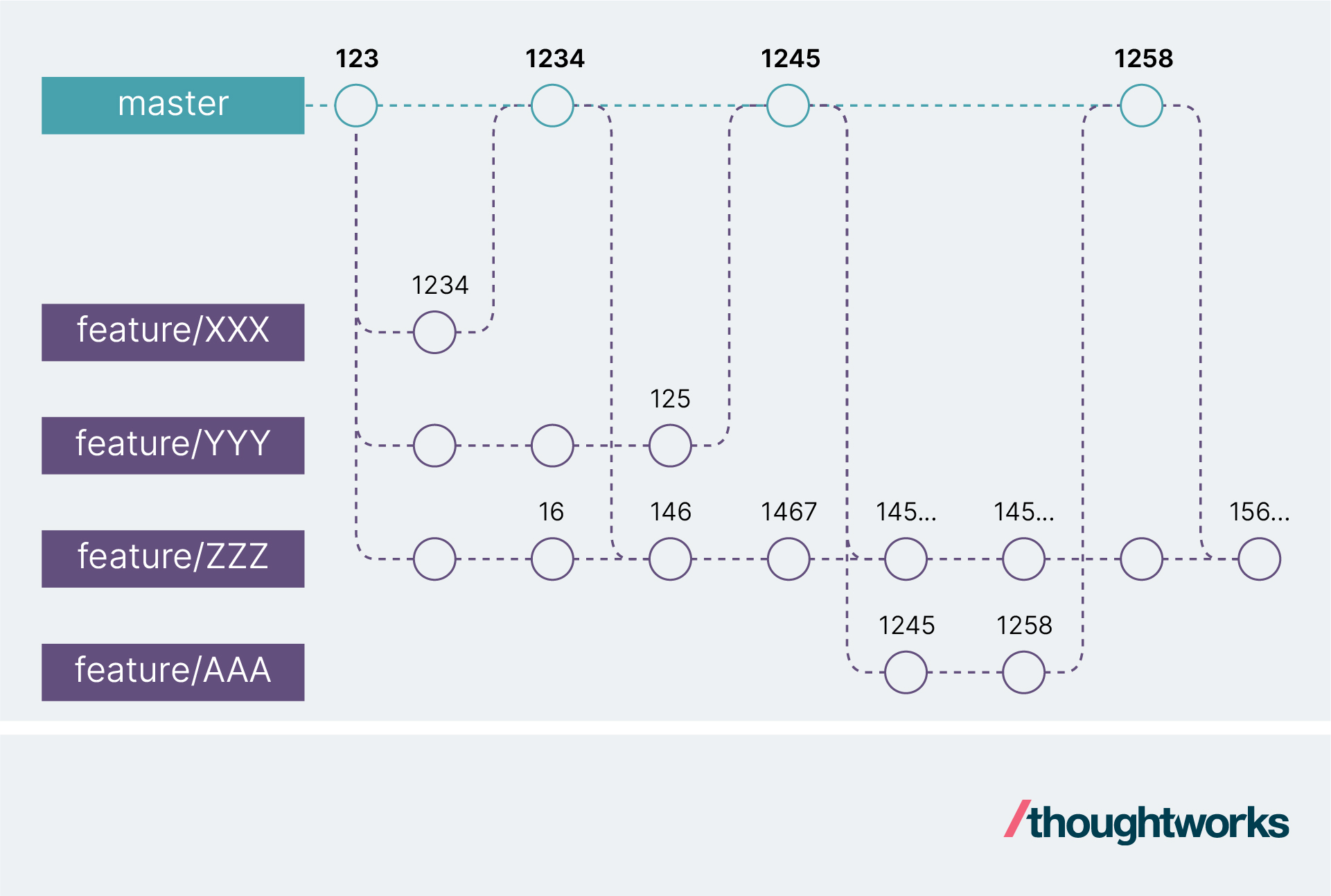
我们来举个例子,如上图所示,XXX、YYY、ZZZ是三个新特性,它们都要修改同一个文件(文件内容为“123”),XXX和YYY为当前迭代交付,ZZZ是个大需求,需要跨迭代交付。开发和集成过程是下面这样的:
XXX需求将代码改为“1234”,开发完成后合并到主干
ZZZ需求将代码改为“16”(删除了23,添加了6),然后feature/ZZZ分支将主干上的代码拉取到本地,代码合并为“146”(删除23,添加46),并进行集成
YYY需求将代码改为“125”(删除了3,添加了5),开发完成后合并到主干。这时主干代码变为“1245”(删除了3,添加了45)
ZZZ需求继续将代码修改为“1467”(添加了7),然后feature/ZZZ分支将主干上的代码拉取到本地,代码合并为“14567”(删除了23,添加了4567)
下一个迭代的新需求AAA从主干上拉取分支feature/AAA,此时feature/AAA代码为“1245”,这与feature/ZZZ分支上的“14567”已经有非常大的差别了
AAA需求将代码改为“1258”(删除了4,添加了8),开发完成后合并到主干
ZZZ需求将代码改为“14569”(添加了9),然后feature/ZZZ分支将主干上的代码拉取到本地,代码合并为“15689”
在这样的基础上再进行开发,feature/ZZZ分支每次拉取主干都需要进行大量的合并工作,并且这些工作还是重复的(比如每次合并都要删除一次2)。这里还只是删除和新增代码,不涉及修改。假设ZZZ和AAA都修改了5,那合并的难度就会成倍地增加。
这个例子只修改了同一个文件,可能显得有些极端,但对于超长特性分支的害处还是可见一斑的。
最有可能产生合并问题的是代码重构。如果一个人重构了一个类,提取了几个小方法,另一个人恰好在原来的代码基础上修改了这个类,那么几乎肯定会产生大面积冲突。因此,采用特性分支的项目实际上等同于放弃了重构的机会,而缺乏定期重构的系统很容易腐化。
长分支、晚合并和延迟集成,这是在前DevOps时代最显著的软件开发问题。没想到在许多年后的今天依然困扰着众多研发组织。为了避免上述问题,很多组织会选择以下应对措施,然而这些措施并没有真正从正面解决问题,反而会引入其他新的问题:
单兵模块:即一个人负责一个模块,多人之间不会产生修改相同文件的情况,从而避免冲突。我们有的时候会给不同团队划分代码责任田,以便于管理。但这种“单人代码责任田”时间长了容易形成知识孤岛,造成单点依赖,同时也容易形成下面所说的“代码复制”。此外,一个人维护一个模块往往会超出认知负载,产生很多隐患。
代码复制:遇到可能修改相同代码的时候,把代码复制出来一份做相应的修改,而不是在原来代码的基础上修改。时间长了代码会质量严重下降,增加了维护成本。
cherry-pick:如果万不得已修改了相同的文件,则把其他人的提交cherry-pick到自己的特性分支上来。但这增加了编写代码时的认知负载,修改的文件多了容易乱掉。
预集成流水线:在真正合并到主干或公共分支之前,先在一个临时分支上进行合并并触发流水线,以检验集成的质量。然而这充其量部分解决了合并质量的问题,但并没有从根本上解决合并痛苦的问题。
由于知识孤岛和代码质量下降问题需要很长时间才会体现出来,因此单兵模块和代码复制配合特性分支似乎可以完美“解决”合并冲突,这使得特性分支成为了很多研发组织中的“最佳实践”。
然而实际的情况却是,知识孤岛和代码质量的问题早晚都会爆发,只是时候未到。
使用反模式的原因
研发组织之所以选择使用特性分支,主要原因有两个。
第一个原因是希望将PR评审作为质量门禁,没有通过评审的代码不会合并到主干中。 这样一来,即便团队成员水平参差不齐,也仍然能够通过PR评审来保障代码质量。于是就会鼓励开发人员在开发之前先拉一条特性分支。
二是因为很多软件特性的上线时间并不确定,为了不影响正常发布,开发团队于是决定在特性开发完成前不合并到主干或公共分支。
之所以特性的上线时间不确定,一方面是项目管理的问题,无法正确地估算特性的开发时间,另一方面是需求管理的问题,无法将大需求拆分成可分批独立上线的小需求。当然,还有一种原因是由于产品定位改变或法律法规变化等不可抗力而不得不取消上线。
你会发现,不管是人员能力还是项目管理、需求管理,问题都是出现在上游,而解决方案却是在下游(技术上的特性分支、单兵模块、代码复制、预集成流水线等)。头疼医脚,最终结果就是脑袋大了,腿脚也不好使了。
变种:AoneFlow
基于特性分支的变种有很多,这里我只分析最典型的AoneFlow[6]。由于出身名门,使得一众团队趋之若鹜。但实际上,AoneFlow与特性分支一样,并没有解决持续集成的问题,它甚至没有理解什么是持续集成。
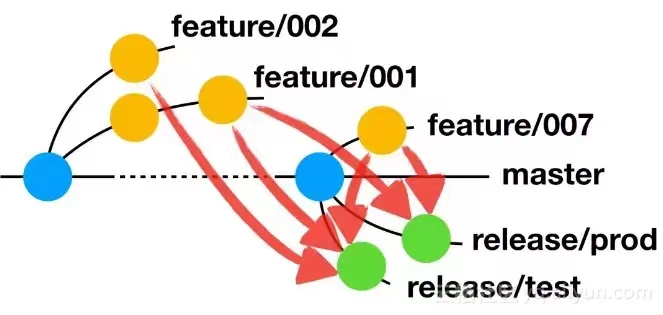
AoneFlow
AoneFlow的诞生是为了解决在特性分支策略下,一个特性延迟上线后造成的发布分支无法正常发布问题。例如特性A开发完成后合并到了发布分支,但产品团队临时决定不上这个特性,这时revert代码的风险非常高。而AoneFlow可以灵活地重新拉取一个新分支,其他特性再重新合并到这个新分支上,从而快速构建一条不含特性A的新发布分支。
为什么说它并没有解决持续集成的问题呢?
它和特性分支一样,是开发完成后才合并回发布分支,所以仍然是延迟集成。 如果开发在一天(最多两天)内完成,那似乎问题不大,但一旦超过两天,就和长特性分支没什么区别了。
如果不是开发完合并而是鼓励每日合并,但特性分支不会合并发布分支的代码,会导致每次合并都产生冲突(因为分支的head不一样)。开发人员会在一定程度上排斥合并和集成。
重建发布分支时不得不把之前的合并冲突再解决一遍。 假设特性B和特性C有冲突,在第一次合并的时候需要解决一次冲突。当特性A不上需要重建发布分支时,特性B和特性C仍然要解决一次冲突。由合并产生风险的可能性翻倍了。
所以要想使用AoneFlow需要具备一些前提:
特性拆分得很细可以快速开发完成
特性之间的依赖很少,不会产生严重的合并冲突
有工具支持可以快速合并
因此,大厂也许可以玩转AoneFlow,但普通开发团队恐怕只能东施效颦。
替代模式
特性分支这个解决方案产生的路径可能如下所示:
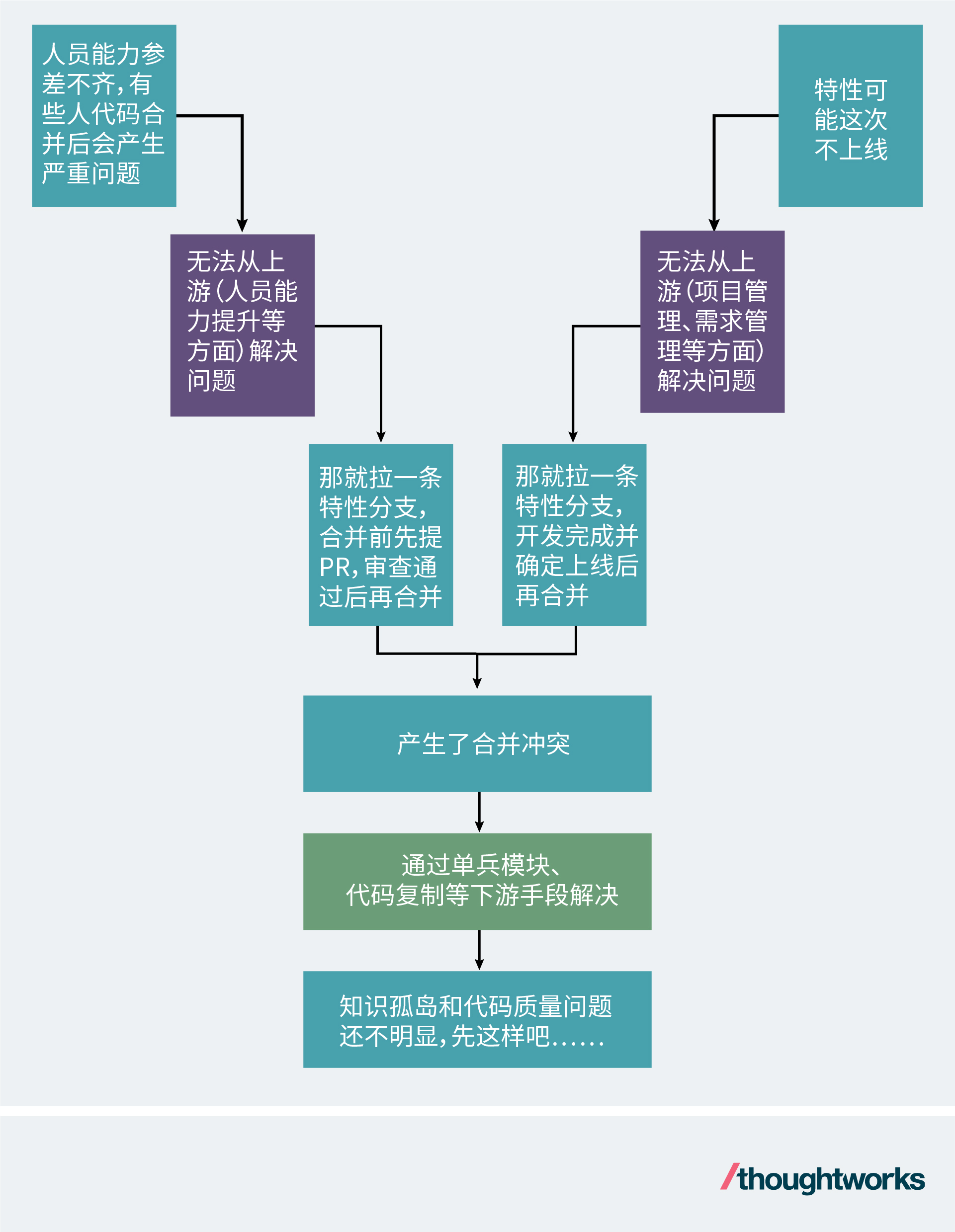
显然,上游的问题就该从上游取解决。团队应该增强开发、需求管理和项目管理能力,组织招聘和培训,并尽可能细粒度地拆分需求,制定更合理的发布计划。
而下游的分支策略,就应该采用最简单且最有效的主干开发。如果由于不可抗力原因导致已经在主干或发布分支上的特性需要回滚,就使用特性开关。
主干开发
基于主干开发的分支策略(或其变体,如公共的开发分支或发布分支,或较短的特性分支)是唯一能够支持持续集成的分支策略。无论是《持续交付》[7]还是《DevOps实践指南》[8],都把主干开发作为唯一有效的分支实践。
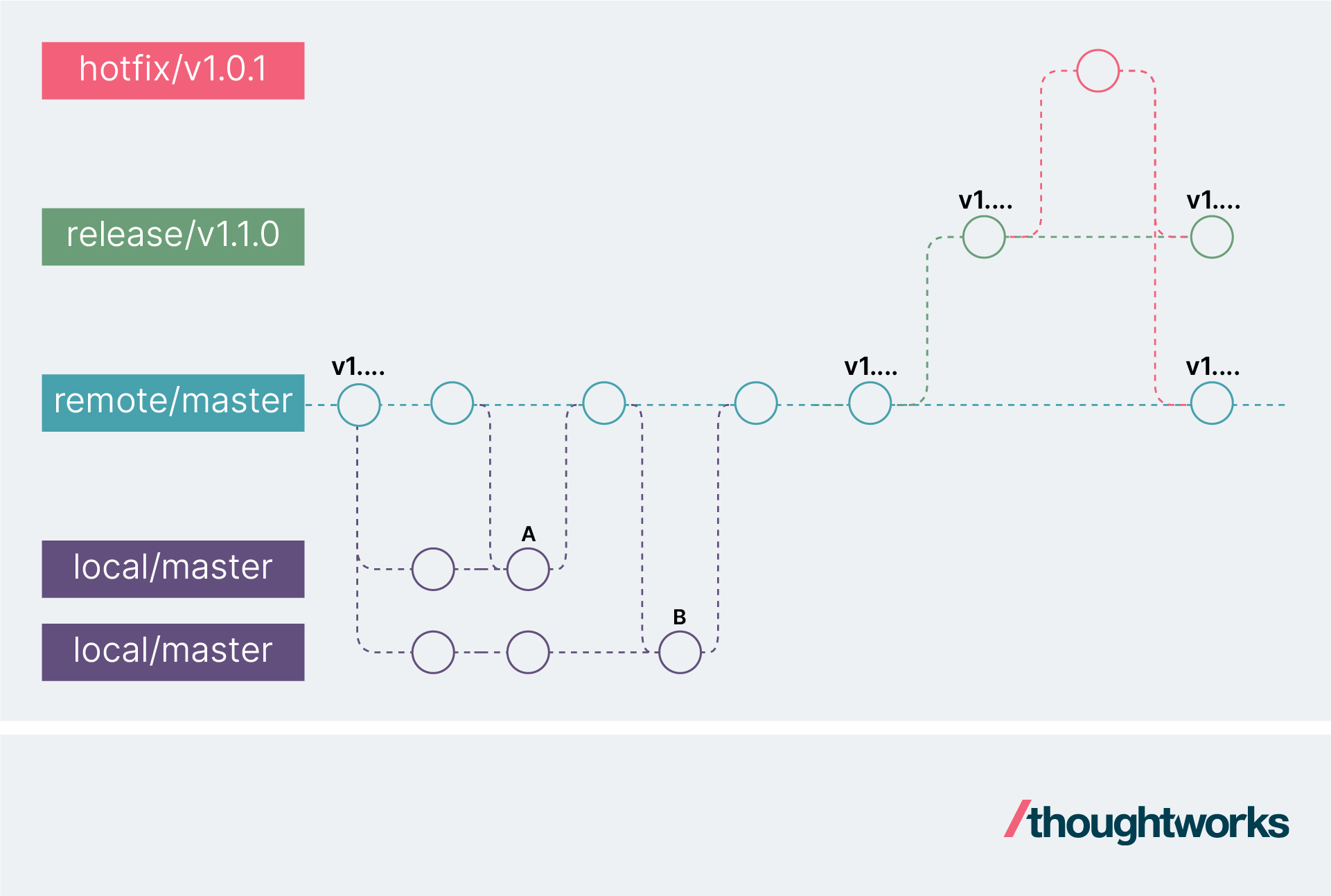
主干开发的流程如下:
每个开发人员在本地的主干分支上修改代码(也可以在本地的特性分支上修改代码,只要满足2即可)
开发人员每日多次向远程主干合并代码,在合并前先拉取(pull)远程主干上的代码,在本地进行合并(merge/rebase),然后再推送(push)到远端
发布和hotfix流程与之前提到的特性分支类似
可以看到,主干开发与特性分支最大的不同,就是每日多次合并代码。这里的合并不仅仅是把本地代码合并到主干,而是本地也要拉取代码进行集成,确保推送之后本地和主干代码是一致的。这样后续的代码才不至于产生更多的冲突。每次集成,都会减少下次集成的工作量。 这是持续集成的前提,反观特性分支和AoneFlow都做不到这一点。
特性开关
前面说了,特性分支广为流传的原因之一就是特性回滚。一来需求管理和项目管理能力不足,无法确定需求的准确发布时间。二来也有可能需求开发完了却由于种种原因不上线了。这时如果是主干开发,不上线的代码已经集成到了主干上,很可能导致系统行为与预期不符。这就需要把已经合并到主干或公共分支上的该特性相关的代码回滚。而git revert回滚会造成大规模冲突,直接删除代码又容易改出问题。所以开发团队干脆选择在特性确定上线之前不合并代码。
这本质上是一种逃避。其实业界早已有了应对特性回滚的最佳实践,那就是特性开关。
使用特性开关的常见流程如下:
尽早发现当前特性无法在当前发布周期发布
添加特性开关,使得只有在开关打开时才会运行与当前特性有关的代码,特性关闭时依然运行老代码
在测试当前特性时,打开开关;测试其他特性时,关闭开关
当前发布周期结束时,关闭开关,发布
进入下一个发布周期,直到特性开发完成并测试通过,删除开关
用一句话总结就是,开关打开时,运行相关的代码,开关关闭时,不运行相关的代码,系统行为与没有这段代码时无异。这样,如果相关代码不上线,我们只需要关闭开关就可以了。
特性开关不仅可用于特性回滚,还可以用于大规模重构、模块/服务绞杀等场景。
使用特性开关时要注意,一个特性开关的存活周期不能太长,否则容易出现多个开关一团乱麻的情况,这跟分支的生命周期不要太长是一个道理。也没必要每个特性都设置开关。
如何落地
虽然主干开发+特性开关是持续集成的最佳实践,但却很难在研发团队中落地。人们总是能找出各种理由来回避这个方案。其中最常见的理由就是,认为主干开发和特性开关对开发人员要求较高,当前团队成员无法实现较好地开发和管理特性开关。这其实也是一种误区。团队成员能够适应繁琐的特性分支或其他定制化的分支策略,怎么会搞不定特性开关呢?
我曾经辅导过一个客户团队进行遗留系统改造,他们以前就是用特性分支进行开发,并且客户领导明确表示以当前的团队能力是无法胜任主干开发和特性开关。但是对于遗留系统改造来说,我们常常会对代码进行大量的重构,如果不用主干开发,集成时间过晚会造成大面积冲突;在对旧代码/模块的进行绞杀时,也常常会用特性开关来确保安全。所以我还是决定试一试。
由于其他小组仍然在使用特性分支开发其他特性,整个项目也是基于特性分支进行发布,因此我没有进行项目级别的主干开发改造,而是为这个遗留系统改造小组创建了一个单独的公共分支。把这一条公共分支作为主干,不断地将代码集成进来,确保组内的代码做到持续集成。然后又每天会把真正的主干代码合并到公共分支,确保和其他特性的代码进行集成。
而且我们这条公共分支也能做到PR评审,流程是这样的:
开发人员在本地的公共分支上开发代码,开发完毕后将代码推送到远端的一个临时分支上
在git工具上创建一个PR,源分支是这个临时分支,目标分支是公共分支
PR创建后直接批准并合并代码,确保集成尽早发生
小组成员针对这个PR进行代码评审
在进行PR评审时,大多数团队会选择评审通过后才合并代码,而我通常采取的方式是直接批准这个PR,并在每天的代码评审会上集中评审这些已经通过的PR。 如果有问题,就重新在主干上提交代码进行修复。
一般在特性分支模型下,PR只有在评审通过后才会合并;修复PR时,都是直接在特性分支上修改,再更新到这个PR中。这样做的坏处是进一步导致了延迟集成。
经过了1个月左右的培训和辅导,这个10+人左右的小组已经可以熟练掌握主干开发(的某个变种)和特性分支了。
总结
以上就是我们要介绍的第一个反模式,特性分支。它的常见程度、危害程度和治理难度如下所示:
常见程度:★★★★★
国内90%以上的开发团队都在使用基于特性分支的分支策略。
危害程度:★★★★★
根本做不到持续集成,与DevOps的理念和主张背道而驰。可能有些团队暂时没有产生问题,那只是还没有产生而已。或者产生了问题,但把责任归结于负责合并代码的开发人员,而没有意识到这是团队的问题。
治理难度:★★★
只要特性分支能够快速合并到公共分支并删除,或特性分支先拉取公共分支代码再合并到公共分支,然后继续在公共分支上开发剩下的内容,就是某种程度上的主干开发了,就可以做到持续集成。特性回滚的问题可以先尝试从项目管理和需求管理的角度去解决,不行的话再尝试特性开关。
接下来我们还会介绍更多软件开发过程中的反模式,敬请期待。
参考资料
反模式(Anti-pattern)的定义: https://martinfowler.com/bliki/AntiPattern.html
RubyChina上关于Gitflow有害论的讨论: https://ruby-china.org/topics/29263
频率可以降低复杂度: https://martinfowler.com/bliki/FrequencyReducesDifficulty.html
DORA报告: https://dora.community/
合并地狱: https://www.stxnext.com/blog/escape-merge-hell-why-i-prefer-trunk-based-development-over-feature-branching-and-gitflow
AoneFlow: https://developer.aliyun.com/article/573549
《持续交付》: https://book.douban.com/subject/6862062/
《DevOps实践指南(第2版)》: https://book.douban.com/subject/36868981/
Martin Fowler网站上有一篇文章,详述了各种分支模式:https://martinfowler.com/articles/branching-patterns.html
免责声明:本文内容仅表明作者本人观点,并不代表Thoughtworks的立场