














Continuous delivery
Enabling Trunk Based Development with Deployment Pipelines

Continuous Delivery provides great benefits not only for the team developing the software, by increasing their confidence, but also for the product team, since the delivery of new features becomes a pure business decision.
At the center of it all is the delivery pipeline. It shows how the team delivers changes to production and also provides a one stop shop for project quality.
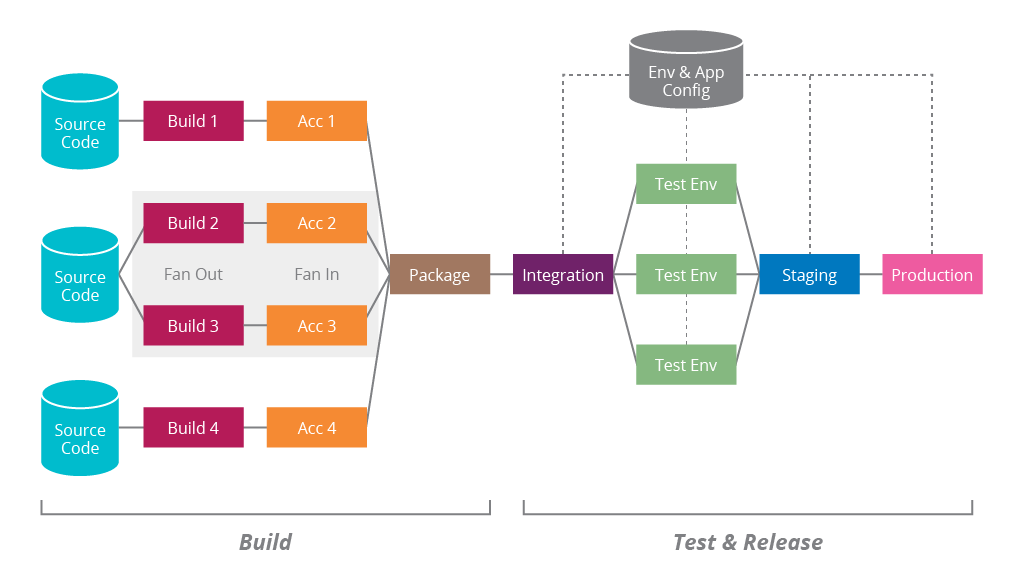
Good pipelines have some key traits that every pipeline should aim to achieve; in this article I'll talk about five that I've observed. It's not an extensive list and of course, every project has its own context that must be respected, but in projects I've worked on, when one of these traits was absent, it has caused the team trouble.
Most pipelines have verifications that range from code linting to full UI based tests. There is no rule to define what goes into a pipeline, but I believe that if it provides useful feedback about quality, it should be in the pipeline.
However, there are some verifications that teams don’t always remember, like the cross-functional tests. These tests are usually about performance, but can test the load the application can take or even look for security breaches.
To ensure the team gets feedback on every change, these tests should be automated as much as possible and should also be a part of the pipeline. Even if the company has a big event to load test all products and ensure the various parts of the product can handle the traffic, a team should still run small load tests as part of the pipeline.
Cross-functional tests usually receive a special treatment in the pipeline. If one of them fails, they don't always need to stop the whole suite. Let's say the performance of the application has dropped below a specified threshold. Does it mean it won't work? Not necessarily.
Instead of failing the build, cross-functional checks should provide actions for the team. This implies that what is measured is also actionable; so the team must consider the context of the project in order to decide what cross-functional tests will be in place and how they'll work.
Going back to the performance drop example, the team should, ideally, be able to track down exactly which part of the app got slower since the last check-in and to investigate possible causes, which leads us to the second trait.
Having quality checks built into the pipeline is great, but the team also needs to receive feedback upon every check in, and it should be fast!
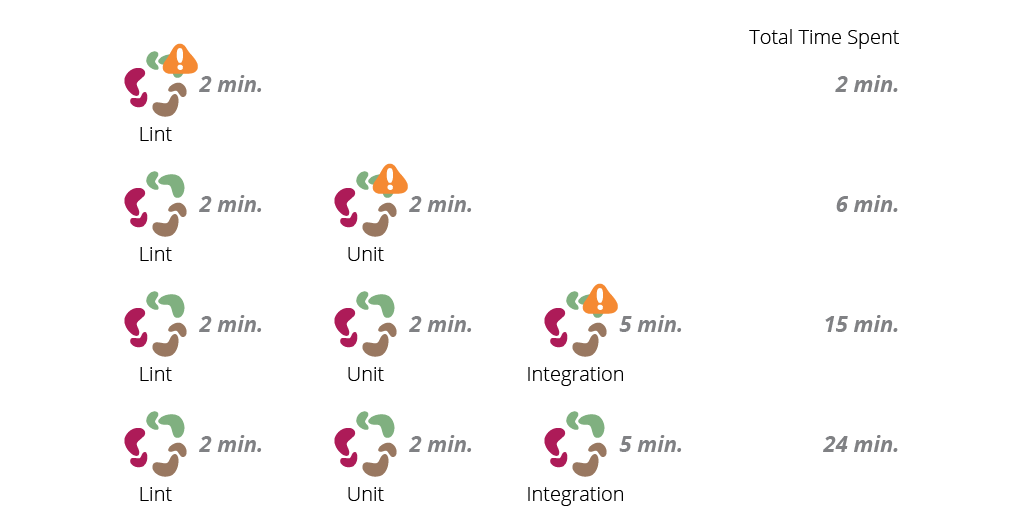
When thinking about providing fast feedback, we must follow the idea of failing as soon as possible. Faster tasks, like code lint or unit tests, should be among the first to run, whereas manual test or performance checks should only happen after we are sure that the code is sound.
Running tasks in parallel is also a great idea to reduce the feedback cycle. For example, let's say that as part of your pipeline you have code lint (which takes 2 minutes), unit tests (another 2 minutes) and integration tests (which take a little longer, 5 minutes). Considering the worst case scenario, where a commit breaks all three jobs, it would take 24 minutes just to get a green build in the sequential pipeline.
Now, if we setup our tasks to run in parallel, and if a code breaks each job, it would only take five minutes for your team to get feedback and another five to get a green build.

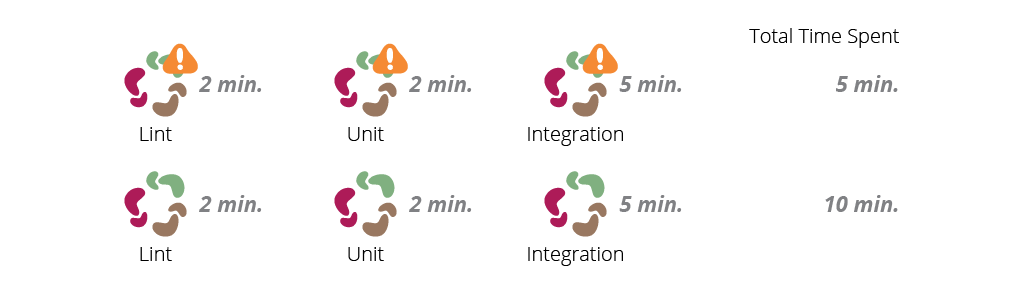
Manual steps, like exploratory and usability testing, have a long feedback cycle—because they depend on humans to poke around the system—and will usually be one of the latest steps executed, but should still be part of the feedback cycle!
For automated steps, we can also check which ones take longer and find a way to improve them.
Another key factor here is to also provide effective feedback. A pipeline job that does a lot of things makes it hard for the team to identify what failed and may hide information. Having small steps, with clear error messages, increases the team's effectiveness when debugging a failure and avoids losing confidence in the pipeline - a.k.a. just re-run the build - it should go green.
As much as we like automation, there is still a need for human interaction in the process of delivering software. But we can work to make this interaction minimal and more effective.
Before any manual testing, it's best to ensure that all automated stages have passed the build in an environment that is as similar to production as your project can afford. This way, not only will the application be tested, but also the configuration in which it will run. Doing that, you can save people's time by avoiding running into environment issues.
Most of the situations where manual testing takes a really long time—like days, weeks or even months—happen because there is little or no interaction at all between the people who run tests and the rest of the team who developed the product. Usually when all deploys need to go through a completely silo-ed QMO (Quality Management Office) first, a lot of time in the team's feedback cycle is consumed.
This doesn't mean that manual tests should be a second class citizen, it just means that people should collaborate to make it more effective—as suggested by the 'Amigos' strategy.

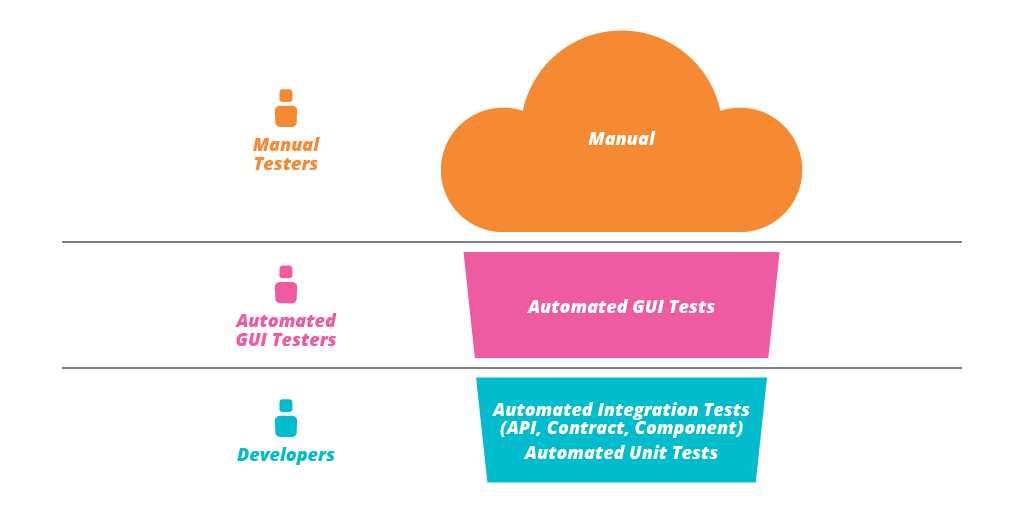
Having functional teams usually leads to a scenario where no one knows about what the other team is doing, so everyone wants to make sure they are doing the best they can. Thus, every piece of functionality is tested through all levels, leading to wasted efforts as described in the testing cupcake anti-pattern.
To achieve minimal manual interaction in the pipeline, leverage the fact that everyone in the team is a human being (yes, that's true!) and just talk to each other.
Whenever an application has to go live, no matter how much the team has tested it before, everybody gets (at least) a bit worried. How can we improve the confidence of what we are deploying? The CD (Continuous Delivery) answer is to make sure you exercise the same process with the same binaries all along the way to production.
A binary in this context is the actual artifact that gets deployed in a server. This may be a system package, the actual source code in a specific tag, a docker image etc. Regardless of what it is, a good pipeline will use the exact same binaries to deploy in all environments, be it the super powerful Stage environment that is used to simulate production or the simple QA that is used for exploration tests.
Another key part is to also use the same process to deploy the binaries. If you have automated scripts to deploy to the QA environment, you should use it to deploy to production - as well as any other environments. If the deploy to production is manual, there is a high chance of human error, ranging from a simple typo to forgetting an important step before turning the servers back up.
Whatever varies from one environment to another should be extracted to configuration files that will serve as input to the automated deploy script. This way, you ensure that the process itself will work when it hits production, although configuration mistakes may still happen.
Automating the deployment process is a good way to kick-start Continuous Delivery in your team/organization. If you can convince people to use automated scripts to deploy all environments, the benefits of CD will start to show up and will get their attention. But keep in mind that automated deploys are just a starting point!
The nirvana of Continuous Delivery is not having daily deploys, or putting every commit in production automatically. It's actually enabling the business to decide when to go live with a feature, without having to ask for permission from the team developing the software. If it makes sense to deploy daily, hourly or monthly, it is up to the product team to decide.
To achieve this, the pipeline must provide an easy way to deploy any version of the application, at any given time. Of course, maintaining a rollback strategy that allows this might be a nightmare, so again the team needs to understand the context of the project and make the best decision. Maybe it makes sense to keep a rollback just for one or two minor versions.
The key point here is to make sure that you can roll forward (deploy a newer version) as easily as you can roll back (deploy an older version), just in case there is a major issue. Ideally, you could always roll forward and disable a broken feature with a feature toggle. I recommend these two articles if you want to know more about the usage of feature toggles: Enabling Trunk Based Development with Deployment Pipelines and On DVCS, continuous integration, and feature branches.
One of the biggest problems when rolling back is to ensure data integrity. Ideally, the team should be able to avoid destructive changes and keep the system compatible with previous versions of the schema. In some scenarios, a database backup might be doable, but the data that is saved during the roll back time will be lost. The book Refactoring Databases, by Scott Ambler and Pramod Sadalage, might be a useful resource.
Making the deployment of any version easy can be a very hard task, but it has benefits not only to the product team, but also for the development team. Imagine something falls apart in production and you receive a call in the middle of the night. You log in and poke around, but can't find anything useful. While you could waste the rest of your night chasing bugs, and potentially ruin the next day as well, a much better option is to say "okay, let's just rollback for now and investigate deeper tomorrow".
I hope this article is useful for you and your team and can help you improve your pipeline even more. Again, this is not an extensive list of what a good pipeline should look like. To have a more comprehensive perspective, don't forget to check the other articles linked here.
Do you feel like something was left out? Do you agree or disagree with this list? Do you have your own set of traits of a good pipeline? Leave a comment here or reach me on twitter @marcosbrizeno.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

