














Mobile is rapidly taking over desktop as a channel to reach customers. In fact, according to Mary Meekers’ 2014 Internet trends, Internet traffic from mobile devices is up from 14% in May 2013 to 25% globally in May 2014. That's significant year-on-year growth. Businesses all around the globe are adapting to include a compelling mobile experience for customers as part of their digital strategy.
Unfortunately, most of the backend systems and services that power mobile apps have a lot of catching up to do. As such, I have had an opportunity to work with several customers to build apps that feed off legacy web services.
In this post I have summarized some of the challenges that I faced while building a mobile app against legacy web services. It also explores an adaptive web service approach that helped us make that journey smoother. Please note web API in current context primarily refers to a web service implementation over HTTP protocol.
The majority of web services that we used to build apps were written long ago. They were often bloated in size and used a relatively older payload format (e.g. SOAP/XML). These services were designed with high bandwidth, low latency considerations and they tend to be verbose and chatty. Only a small subset of information that was part of response, was relevant to us. In addition, data sources were distributed. It required orchestrated service calls with multiple systems. It also forced us to deal with different response formats and do additional work of aggregating fragmented bits of information.
Both these things were redundant and an overhead for each client device. Finally building orchestration logic in app built a tight coupling between app and data sources. Anyone who has released a mobile app would vehemently agree that upgrading all users to the latest version of an app is a non-trivial task. Building orchestration logic in the adaptive layer is a far more feasible way of achieving that decoupling.
To handle some of these challenges we decided to experiment with a simple and yet elegant architectural change of introducing an adaptive web API in the middle.
So What’s Adaptive Web API?
Adaptive web API is a fancy name for an architectural design where a “dumb” proxy/wrapper web service sits in between a consumer app and legacy web service(s). It allows for abstraction of distributed web services, simplifies the contract, aggregates data from multiple sources into unified response, allows flexible selection of payload format and encourages loose coupling among many other benefits. Let’s look at some of these specific points in more detail.
Build a Consumer Friendly Service
Legacy service payload formats like SOAP/XML can be verbose. Teams looking to build highly performance and responsive services would cherish the freedom to choose payload formats and architecture in an already constrained environment.
An adaptive web API layer in between can dramatically improve the control and flexibility a team has in such a scenario. When requests and responses pass through adaptive web service, it can help chaff out bits in response, that are not useful to consumers; making payload optimal for mobile consumption.
To illustrate this from one of the projects where we tried this approach; we had business services that were bloated in size and contained additional information that we didn’t need. Changing the source service would have affected all other consumers. An adaptive web API allows us to simplify the payload format from SOAP/XML to JSON. It further allowed us to trim out unneeded data. This reduced some of the response sizes by 90%. A huge win!
Do note that the proxy layer remains unaware of any business logic and merely transforms incoming XML response from server to outgoing JSON responses on the fly.


Aggregation from Multiple Sources
Our app was built with compelling user experience in mind. To make that happen, we pre-fetched a lot of data up front, originating from different services and sometimes even different systems. An adaptive web layer allowed us to aggregate data from several sources into a unified and trimmed down consistent JSON response.
Another benefit of unified responses was that, when resources didn’t change often, we could leverage server side caching to reduce latency in response time. However, there is another side to it as well; even if one of the resources in unified response changed then cached responses expired even if none of the other resources had changed. But it was only a minor trade off and could be alleviated with upstream caching.
The biggest benefit however of this approach was that we could seamlessly switch data sources at the adaptive web API layer without affecting the consumer app. This allowed even older versions of the app to leverage newer data sources without having to be updated.


Source Abstraction and Greater Control
An adaptive web API approach helped us build loose couplings between consumers and actual data sources. We were able to shield the consumer app from data source changes and its distributed nature. This is probably best explained by a real world example.
In a recent engagement, we were hired to build mobile apps across multiple platforms. When the mobile app development was in progress, a separate team undertook the task to replace the core back end system which was crucial to the functioning of app but had an independent deadline.
This required us to ensure minimal coupling between the data source and app since we knew the system was going to get replaced. An adaptive web API approach allowed us to build that abstraction.
We built a factory in adaptive API such that it could work against two different contracts to produce the same unified response. The factory could invoke appropriate transformer based on a configuration.
This gave us the flexibility to switch that source system with a simple server restart. We were ready and released before the back end system was replaced completely. On the day of the back end service release, we toggled the config and switched to a new source. The ease of transition made the choice of adaptive web API worthwhile.


Putting Legacy to REST
REST has been a defacto choice lately when it comes to building services over HTTP. We wanted to ensure that we leverage all three levels of REST while building an API for our consumer mobile app. (If you are not aware of different levels of constraints of REST, I would encourage you to read about Richardson’s maturity model on Martin Fowlers’ blog.)
Unfortunately, as you would guess it, the existing services didn’t allow us that flexibility. But an adaptive layer in between will do the trick for you.
In previous points we have already seen how SOAP services can be transformed and exposed as JSON services. What is better is that they can even adopt RESTful architecture and make things easier for new age consumers.
We tried to adopt all three levels of REST constraints. Using HATEOAS principle, we added discoverable navigation to web API. This served us well by building loose coupling and abstraction between consumer and resource URIs. As we evolved web APIs and relocated some resources, our consumers remained unchanged and worked seamlessly.
Independent Evolution of Source Services and Consumers
When we built the app, while the core backend system was being replaced; we realized that had it not been for the adaptive web layer, we would have found ourselves pushed into a corner where our release timelines would have heavily depended on the go live of core systems. Our ability to go live frequently and iteratively would have been limited.
Adaptive web API allowed us to stay shielded from that dependency. Our app relied on API that we controlled and deployed as frequently as we deployed our apps. We scheduled additional deployments to ensure that our adaptive web layer stayed in sync with changes happening in backend services. But when that was not happening, we were deploying other features, adding more data sources and building mobile apps.
In short, having that layer of abstraction allowed us to set our own pace of development and release timelines for the app. Both systems could evolve independently, except in a few coordinated checkpoints.

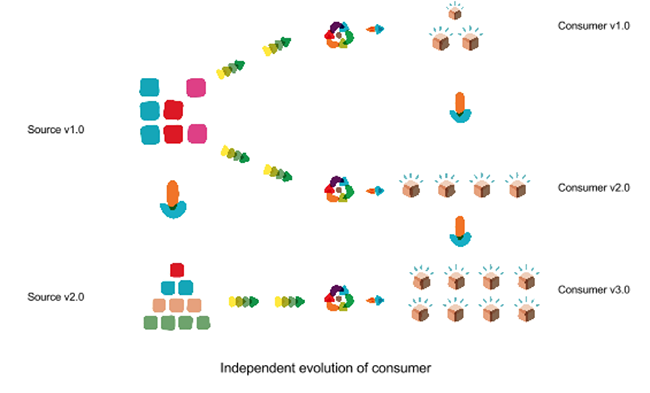
A proxy like middle layer seemed like a trivial architecture decision but had a profound impact on how our apps consumed data and interacted with multiple distributed services. Of course it’s a better fit mostly in an environment that doesn’t offer too much flexibility either because the team doesn’t have control over sources or sources are slow to evolve due to sheer number of consumers. I can also see an argument be made about how a middle layer can cause performance issues.
But I think that it is a minor trade off except in cases where scaling issues trump everything else. Even in those scenarios throwing in more hardware can alleviate it to an admirable degree.
I would also add that although this architectural approach has been discussed in context of mobile apps here, it is applicable to wider spectrum of consumers.
Finally, while naming the approach, I felt that it was the “adaptiveness” of the proxy layer that gave it its strength and hence the name “Adaptive web API.”
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.