














Microservices
Macro trends in the tech industry | April 2019





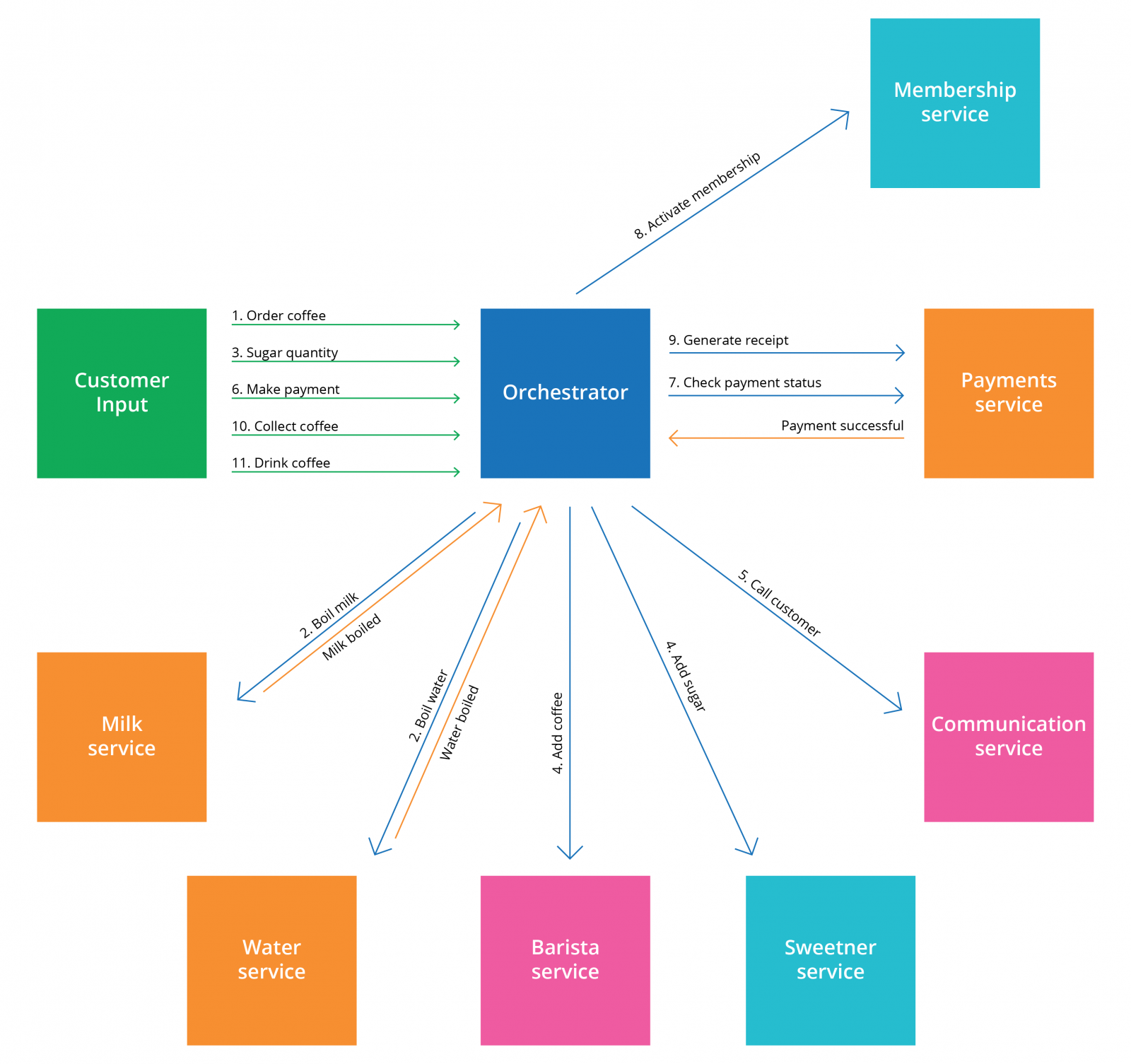
enterCafe .next(orderCoffee) .decisionBranch(COFFEE_WITH_MILK = boilMilk, BLACK_COFFEE = boilWater) .next(getSugarQuantity) .parallel(addCoffee, addSugar) .next(callCustomer) .next(makePayment) .next(checkPaymentStatus) .next(activateCafeMembership) .next(generateReceipt, dependsOn = checkPaymentStatus) .next(collectCoffee) .next(drinkCoffee) .next(leaveCafe)
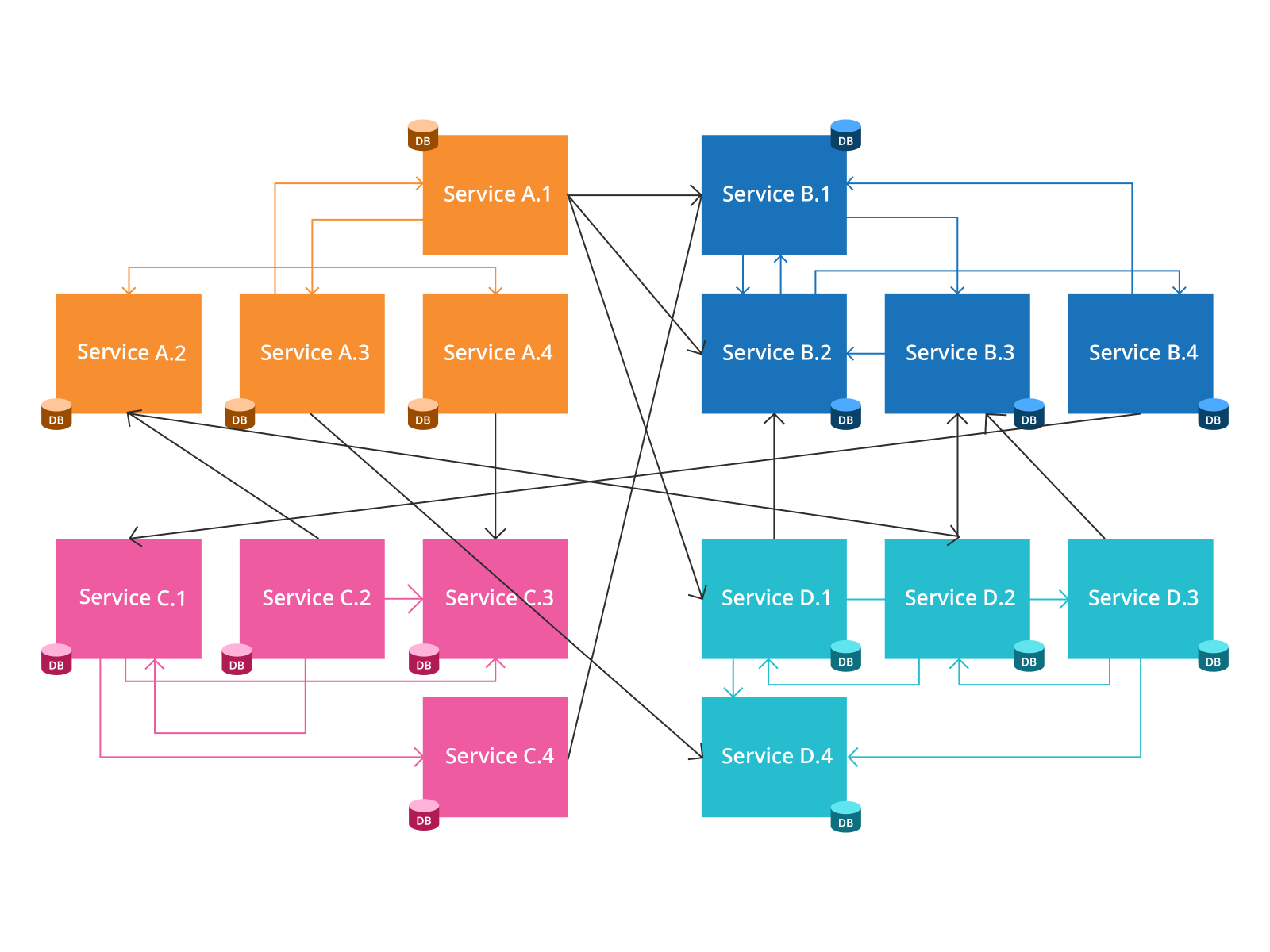
Dependencies help the orchestrator determine when a task can be executed. We wouldn’t want a customer to collectCoffee before all the prerequisite tasks that it has a dependency on are performed. Dependencies can be interpreted either implicitly, based on the process definition or explicitly added.
1. Implicit Dependencies: callCustomer is dependent on addCoffee and addSugar and cannot be executed until they are complete. Such a dependency is implicitly inferred and does not require configuration because addSugar and addCoffee are System Tasks. The same is applicable for a Task after a Customer Task.(addCoffee, addSugar) .next(callCustomer)
makePayment .next(checkPaymentStatus) .next(activateCafeMembership) .next(generateReceipt, dependsOn = checkPaymentStatus)
orderCoffee .decisionBranch(COFFEE_WITH_MILK = boilMilk, BLACK_COFFEE = boilWater)
getSugarQuantity .parallel(addCoffee, addSugar)
class BoilMilk : AsyncStep() {
fun execute() : Temperature {
milkService.boil()
}
fun resume() : Temperature {
this.execute()
}
}
configureCheckpoints(collectCoffee)
configureResetTasks(fromTask = collectCoffee, toTask = getSugarQuantity)
configureNonResettableTasks(activateCafeMembership)
{
"name": "coffee_ordering_process",
"description": "Order coffee",
"version": 1,
"schemaVersion": 1,
"tasks": [
{
"name": "order_coffee",
"taskReferenceName": "order_coffee_task",
"inputParameters": {
"contentId": "${workflow.input.coffee_type}"
},
"type": "SIMPLE"
}
]
}
public class CoffeeOrderingProcess{
private final ActivityOptions options = new ActivityOptions.Builder().build();
private final CoffeeTasks tasks = Workflow
.newActivityStub(CoffeeTasks.class, options);
@WorkflowMethod
public void orderCoffee(String customerName) {
Saga.Options sagaOptions = new Saga.Options.Builder().build();
Saga saga = new Saga(sagaOptions);
String orderCoffeeID = activities.orderCoffee(customerName);
saga.addCompensation(activities::cancelCoffee, orderCoffeeId, customerName);
}
}
public class CoffeeTasks {
public String orderCoffee(String customerName) {
System.out.println("orderCoffee for " + customerName);
return UUID.randomUUID().toString();
}
public String cancelCoffee(String customerName) {
System.out.println("cancelCoffee for " + customerName);
return UUID.randomUUID().toString();
}
}
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

