

















Technology strategy
Risk-based failure modelling for increased resilience

If you’re one of the millions of customers impacted by banking services outages in the past few years, you no doubt appreciate the real pain involved. But if you’re responsible for the running of those services, you’ll have seen the damage to your customer reputation.
In 2020, an India-based bank’s internet and payment services were disrupted, which resulted in a significant number of their 58 million customers not being able to transact. In 2023, a Singapore-based bank’s online and mobile banking services were disrupted, causing 6 million customers to lose access to their accounts for six hours. In 2018, a UK-based bank’s 2 million customers could not access their current accounts via phone, online or at the branch and it took eight months to return to normalcy.
Adding to the pressure on financial institutions, those outages have put regulators on high alert. In several cases, regulators fined banks or restricted the products banks were able to issue.
Today’s banking systems are incredibly complex and there may be myriad reasons for systems failure. But dive into those incidents and a pattern begins to emerge. Here, we outline six common factors that contribute to the erosion of resilience.
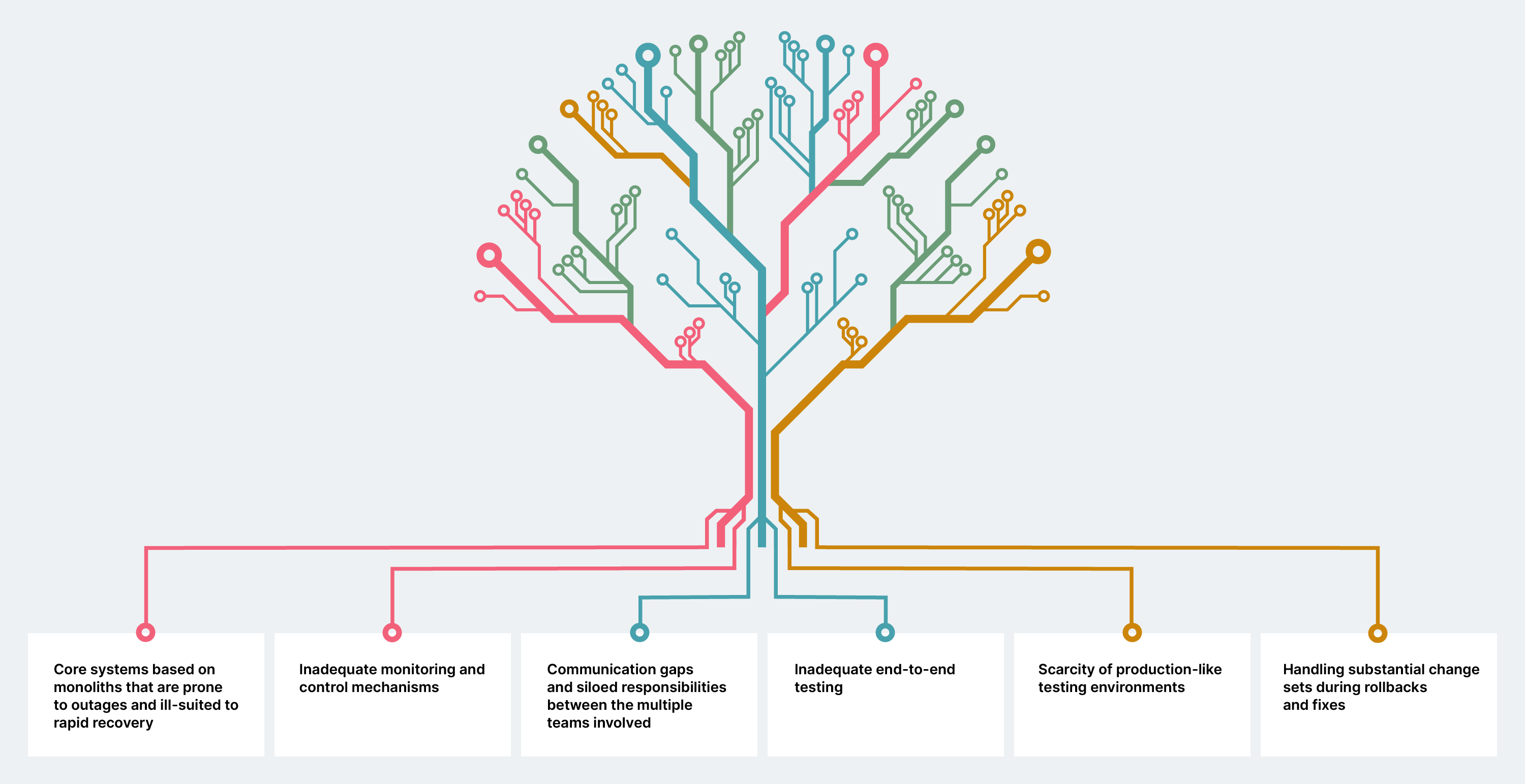
By addressing these root causes, financial institutions can rapidly improve their resilience, curtail outages and uphold the continuity of critical services.
Here’s how we believe that these root causes can be addressed :
| Root cause | Probable solution |
| Core systems based on monoliths that are prone to outages and ill-suited to rapid recovery |
|
| Inadequate monitoring and control mechanisms |
|
| Communication gaps and siloed responsibilities between the multiple teams involved |
|
| Inadequate end-to-end testing |
|
| Scarcity of production-like testing environments |
|
| Handling substantial change sets during rollbacks and fixes |
|
So, how can we overcome some of these roadblocks and obstacles to resilience? There are a few key issues we need to work hard to address.
Not taking a holistic view
Banks often struggle to achieve system resiliency due to their complex IT ecosystems and lack of a holistic view. These challenges are compounded when leadership treats resilience as purely a technology problem — it should be a strategic business requirement. This fragmented perspective leads to piecemeal initiatives that increase the risk of blind spots, and make it challenging to identify or address vulnerabilities. The difficulty in gaining a holistic view is exacerbated by four common issues:
Legacy systems: Many banks operate with a patchwork of legacy systems that have been developed and integrated over decades. These systems often lack standardized interfaces and data formats, which makes it hard to obtain a comprehensive view of the entire IT landscape.
Mergers, acquisitions and divestitures: Many of today’s banks operate with a patchwork of systems that result from mergers and acquisitions. These systems are unlikely to integrate seamlessly, leading to fragmented data and processes. Divestitures add to the complexity when systems cannot be cleanly decoupled.
Data quality: Inaccurate, inconsistent or incomplete data can lead to incorrect assessments of system resilience. Without reliable data, banks struggle to articulate the overall health of their IT infrastructure.
Complexity: The intricate nature of financial products and regulatory requirements compounds the challenge, hindering a comprehensive grasp of system health and vulnerabilities. These complexities arise from various sources, including essential intricacies, accidental entanglements due to poor practices, and optional intricacies from superfluous features. The accidental and optional complexities can be particularly elusive when seeking a holistic view, impeding system resilience.
Applying point solutions or “band-aid” fixes
It's not uncommon for banks and other organizations to apply point solutions or "band-aid" fixes to their software and IT ecosystem in an attempt to address immediate issues or challenges. While these short-term solutions might provide a temporary fix, in so doing, this creates so-called technical debt — which increases the risk of system outages and disruptions. Tech debt is shorthand for those decisions to make short-term fixes that solve a specific issue at the expense of long-term predictability and resilience. Troubleshooting and diagnosis then become challenging, undermining the intended stability. Here are some ways this can happen:
Complexity and integration: In a resilient IT environment, simplicity and seamless integration are key. Applying point solutions that add complexity undermines resilience by increasing the potential for system conflicts, making it harder to diagnose and address issues promptly.
Unintended consequences: Resilience depends on predictability and well-understood system behavior. Unintended consequences from quick fixes can disrupt this predictability, potentially causing outages and undermining the bank's ability to respond effectively.
Maintainable testing: Resilient systems require rigorous testing and enduring solutions. Inadequate testing of band-aid fixes can introduce vulnerabilities or cause unforeseen problems, eroding the system's resilience and affecting the bank's ability to withstand disruptions.
Delayed modernization: Resilience involves adapting to changing circumstances and technologies. Relying on short-term solutions can impede a bank's ability to modernize its IT infrastructure, weakening its overall resilience and making it less prepared for future challenges.
Overwhelmed by bank-wide issues like test environments and end-to-end testing
Implementing comprehensive end-to-end testing can be challenging due to the complexity of banking systems, diverse technologies, and the need for meticulous planning and coordination. Testing must cover various scenarios, including positive and negative user interactions, error handling, data validation and more. Additionally, the ever-evolving nature of technology and the introduction of new services can add complexity to the testing process. While achieving full end-to-end testing across all systems and customer journeys can be a demanding task, it's a critical practice for banks to ensure reliability, security and a positive customer experience in today's highly interconnected and digital banking landscape.
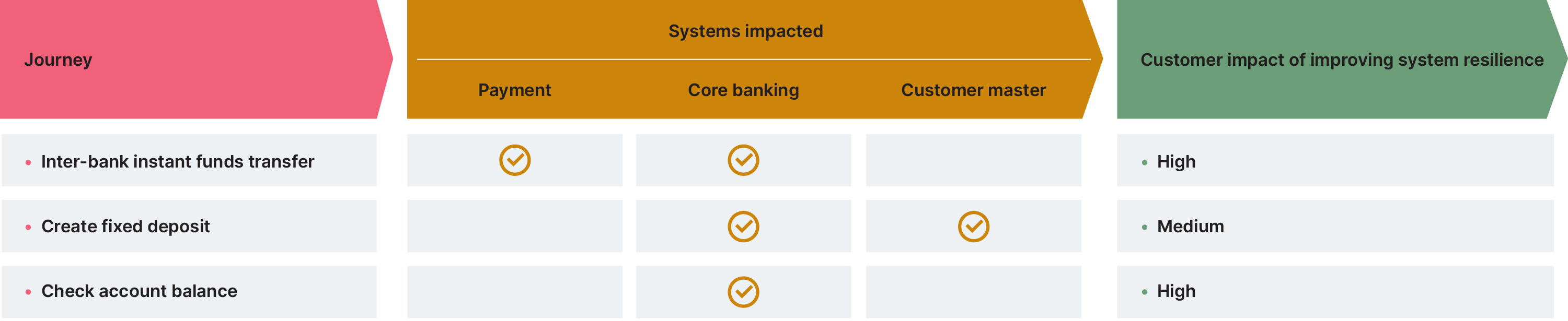
As we’ve noted, many leaders within the banking industry overlook the importance of systems resilience until it’s too late. That why, if you want to gain buy-in before you’ve hit crisis point, it pays to pick a customer or regulatory journey where the impact of the improved system resilience can be felt. This would, of course, need to be weighed against other factors which might increase the scope of the initiative to a point where we are no longer ‘starting small’. Such factors include the number of systems the journey touches (the aim would be to reduce our blast radius) and dependency on other journeys on the systems involved (the aim would be to reduce dependencies). Illustratively, it could look like this :
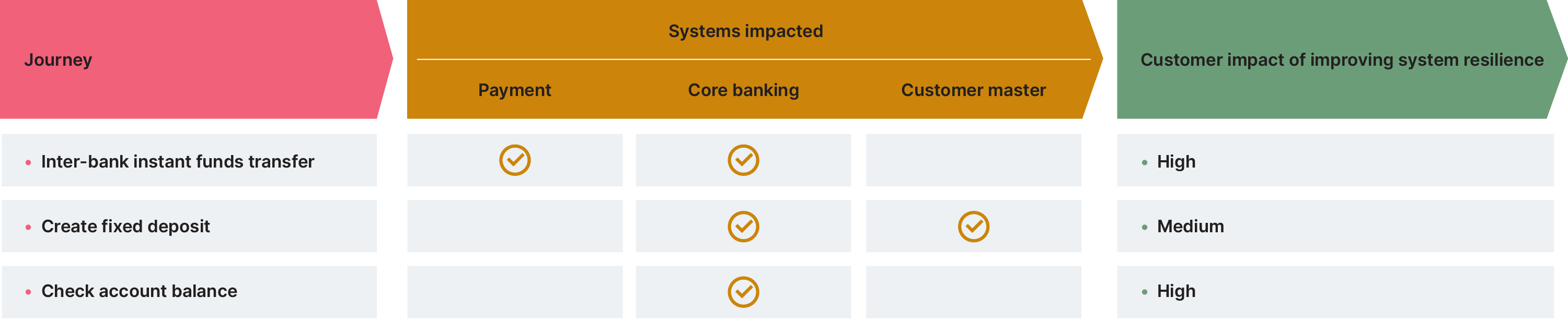
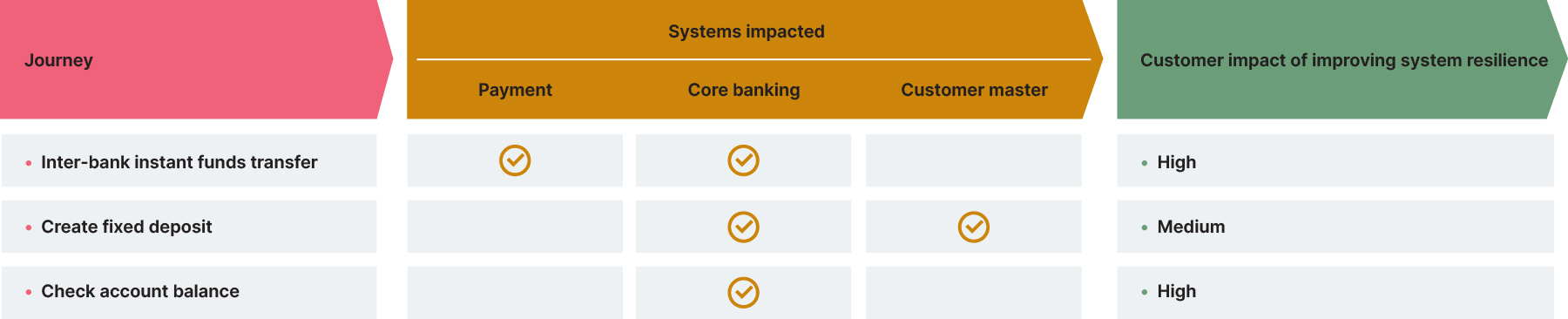
In this example, you might consider prioritizing the check account balance journey as it has a high impact on customers in terms of improved resilience, while not having a huge blast radius in terms of impacting other journeys or systems.
Next, conduct a current state assessment to understand where we stand versus the root causes outlined earlier — some of the root causes might not apply to this case, or the bank may have initiatives underway that are already tackling some root causes. The goal of the assessment would be to identify the specific issues that could lead to outages in the pilot journey and then formulate a plan with solutions for these, with clearly outlined measures of success.
The strategy for scaling up the initiative is as important as the one employed for defining the pilot journey. Once you attain the measures of success for the pilot journey, it would make sense to look at journeys touching systems that were involved in the pilot journey to select the next set of journeys to scale the initiative.
To reduce the risks of system outages, banks need to address root causes and adopt a holistic approach to bolster system resilience. That means recognizing that system resilience is not a luxury but a critical necessity — failing to do so jeopardizes not only customer experience but also regulatory compliance and overall trust. Quick fixes and fragmented solutions prove inadequate, requiring a comprehensive strategy to withstand disruptions.
System resilience isn't a one-time fix but an ongoing cultural shift within banks. It's an evolving journey that demands a holistic approach, modernization, rigorous testing, and collaboration. By embracing these, banks can regain customer trust and navigate the complex landscape of digital banking with resilience and reliability.
Disclaimer: The statements and opinions expressed in this article are those of the author(s) and do not necessarily reflect the positions of Thoughtworks.

